
Large-scale Reconstruction
3D reconstruction is the process of capturing the shape and appearance of real objects. This process can be accomplished either by active or passive methods. If the model is allowed to change its shape in time, this is referred to as non-rigid or spatio-temporal reconstruction. It is a generally scientific problem and core technology of a wide variety of fields, such as computer graphics, computer animation, computer vision, medical imaging, computational science, virtual reality, digital media, etc.
Paper
H. Ying, J. Zhang, Y. Chen, Z. Cao, J. Xiao, R. Huang, L. Fang,
Proc. of The 30th ACM International Conference on Multimedia (MM' 22).
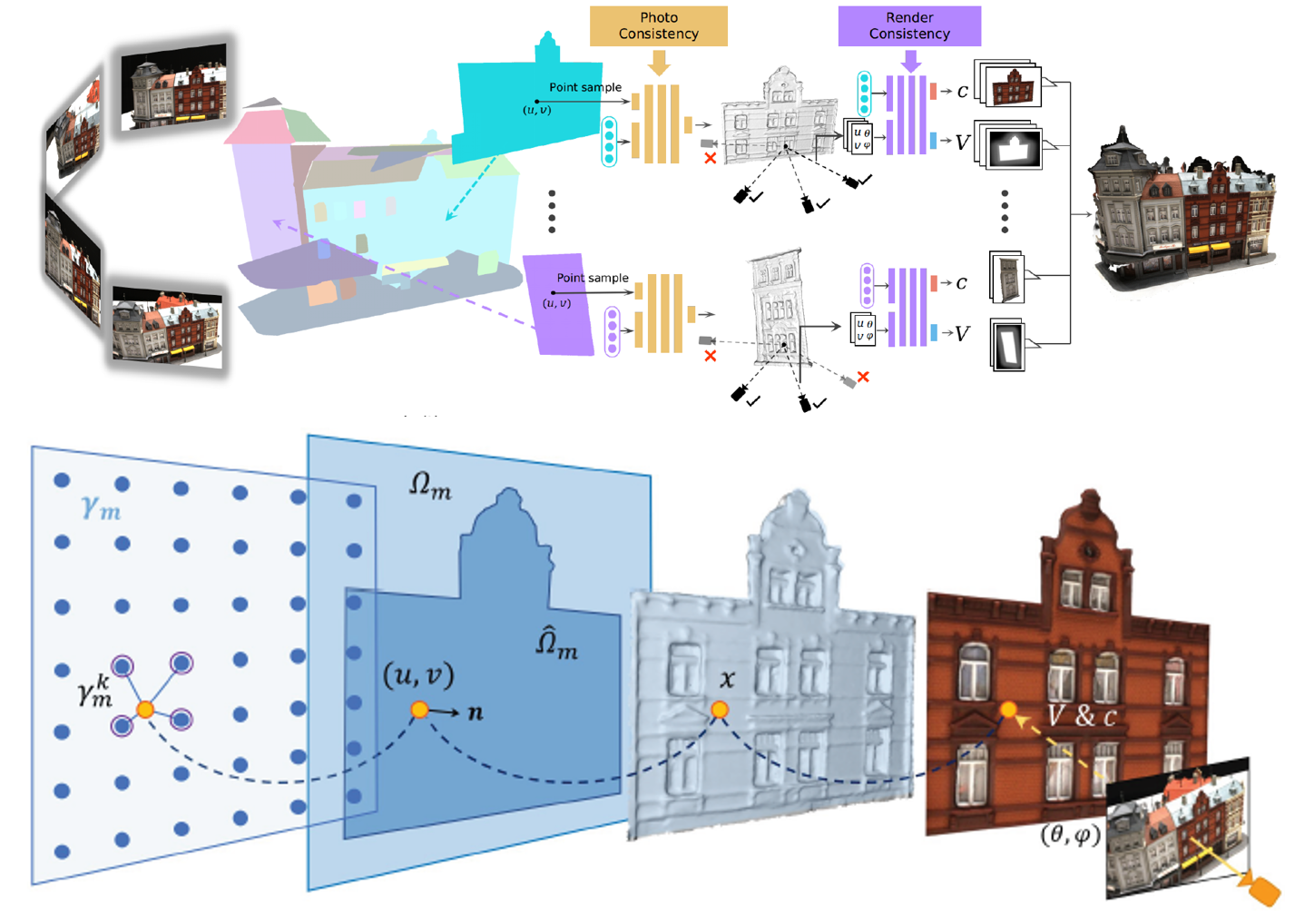
Multi-view stereopsis (MVS) recovers 3D surfaces by finding dense photo-consistent correspondences from densely sampled images. In this paper, we tackle the challenging MVS task from sparsely sampled views (up to an order of magnitude fewer images), which is more practical and cost-efficient in applications. The major challenge comes from the significant correspondence ambiguity introduced by the severe occlusions and the highly skewed patches. On the other hand, such ambiguity can be resolved by incorporating geometric cues from the global structure. In light of this, we propose ParseMVS, boosting sparse MVS by learning the Primitive-AwaRe Surface rEpresentation. In particular, on top of being aware of global structure, our novel representation further allows for the preservation of fine details including geometry, texture, and visibility. More specifically, the whole scene is parsed into multiple geometric primitives. On each of them, the geometry is defined as the displacement along the primitives’ normal directions, together with the texture and visibility along each view direction. An unsupervised neural network is trained to learn these factors by progressively increasing the photo-consistency and render-consistency among all input images. Since the surface properties are changed locally in the 2D space of each primitive, ParseMVS can preserve global primitive structures while optimizing local details, handling the ‘incompleteness’ and the ‘inaccuracy’ problems. We experimentally demonstrate that ParseMVS constantly outperforms the state-ofthe-art surface reconstruction method in both completeness and the overall score under varying sampling sparsity, especially under the extreme sparse-MVS settings. Beyond that, ParseMVS also shows great potential in compression, robustness, and efficiency.
Latex Bibtex Citation:
We propose INS-Conv, an INcremental Sparse Convolutional network which enables online accurate 3D semantic and instance segmentation. Benefiting from the incremental nature of RGB-D reconstruction, we only need to update the residuals between the reconstructed scenes of consecutive frames, which are usually sparse. For layer design, we define novel residual propagation rules for sparse convolution operations, achieving close approximation to standard sparse convolution. For network architecture, an uncertainty term is proposed to adaptively select which residual to update, further improving the inference accuracy and efficiency. Based on INS-Conv, an online joint 3D semantic and instance segmentation pipeline is proposed, reaching an inference speed of 15 FPS on GPU and 10 FPS on CPU. Experiments on ScanNetv2 and SceneNN datasets show that the accuracy of our method surpasses previous online methods by a large margin, and is on par with state-of-the-art offline methods. A live demo on portable devices further shows the superior performance of INS-Conv.
Latex Bibtex Citation:
@inproceedings{liu2022ins,
title={INS-Conv: Incremental Sparse Convolution for Online 3D Segmentation},
author={Liu, Leyao and Zheng, Tian and Lin, Yun-Jou and Ni, Kai and Fang, Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18975--18984},
year={2022}
}
L. Han, D. Zhong, L. Li, K. Zheng and L. Fang,
IEEE Trans. on Image Processing (TIP), Feb. 2022.
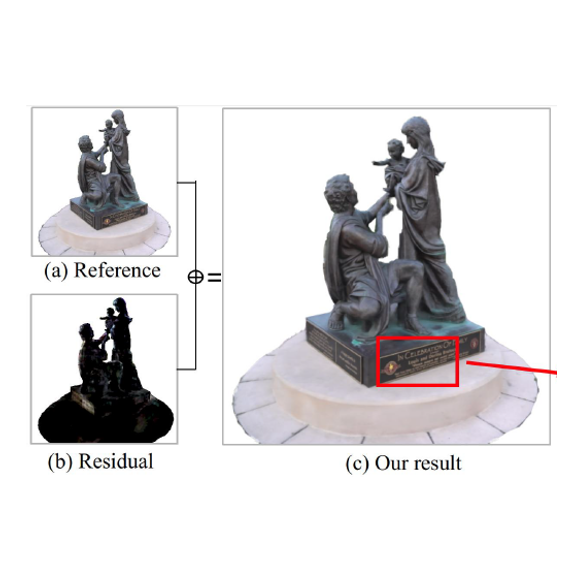
Scene Representation Networks (SRN) have been proven as a powerful tool for novel view synthesis in recent works. They learn a mapping function from the world coordinates of spatial
points to radiance color and the scene’s density using a fully connected network. However, scene texture contains complex high-frequency details in practice that is hard to be memorized by
a network with limited parameters, leading to disturbing blurry effects when rendering novel views. In this paper, we propose to learn ‘residual color’ instead of ‘radiance color’ for novel view synthesis, i.e., the residuals between surface color and reference color. Here the reference color is calculated based on spatial color priors, which are extracted from input view observations. The beauty of such a strategy lies in that the residuals between radiance color and reference are close to zero for most spatial points thus are easier to learn. A novel view synthesis system that
learns the residual color using SRN is presented in this paper. Experiments on public datasets demonstrate that the proposed method achieves competitive performance in preserving highresolution details, leading to visually more pleasant results than the state of the arts.
Latex Bibtex Citation:
@article{Han2022,
author = {Han, Lei and Zhong, Dawei and Li, Lin and Zheng, Kai and and Fang, Lu},
title = {Learning Residual Color for Novel View Synthesis},
journal = {IEEE Transactions on Image Processing (TIP)},
year = {2022},
type = {Journal Article}
}
J. Zhang, M. Ji, G. Wang, X. Zhiwei, S. Wang, L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2021.
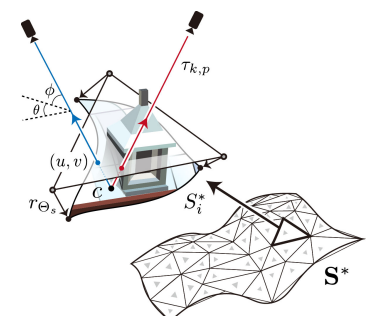
The recent success in supervised multi-view stereopsis (MVS) relies on the onerously collected real-world 3D data. While the latest differentiable rendering techniques enable unsupervised MVS, they are restricted to discretized (e.g., point cloud) or implicit geometric representation, suffering from either low integrity for a textureless region or less geometric details for complex scenes. In this paper, we propose SurRF, an unsupervised MVS pipeline by learning Surface Radiance Field, i.e., a radiance field defined on a continuous and explicit 2D surface. Our key insight is that, in a local region, the explicit surface can be gradually deformed from a continuous initialization along view-dependent camera rays by differentiable rendering. That enables us to define the radiance field only on a 2D deformable surface rather than in a dense volume of 3D space, leading to compact representation while maintaining complete shape and realistic texture for large-scale complex scenes. We experimentally demonstrate that the proposed SurRF produces competitive results over the-state-of-the-art on various real-world challenging scenes, without any 3D supervision. Moreover, SurRF shows great potential in owning the joint advantages of mesh (scene manipulation), continuous surface (high geometric resolution), and radiance field (realistic rendering).
Latex Bibtex Citation:
@ARTICLE{9555381,
author={Zhang, Jinzhi and Ji, Mengqi and Wang, Guangyu and Zhiwei, Xue and Wang, Shengjin and Fang, Lu},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={SurRF: Unsupervised Multi-view Stereopsis by Learning Surface Radiance Field},
year={2021},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2021.3116695}}

T. Zheng, G. Zhang, L. Han, L. Xu and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
Scalable geometry reconstruction and understanding is an important yet unsolved task. Current methods often suffer from false loop closures when there are similar-looking rooms in the scene, and often lack online scene understanding. We propose BuildingFusion, a semantic-aware structural building-scale reconstruction system, which not only allows building-scale dense reconstruction collaboratively, but also provides semantic and structural information on-the-fly. Technically, the robustness to similar places is enabled by a novel semantic-aware room-level loop closure detection(LCD) method. The insight lies in that even though local views may look similar in different rooms, the objects inside and their locations are usually different, implying that the semantic information forms a unique and compact representation for place recognition. To achieve that, a 3D convolutional network is used to learn instance-level embeddings for similarity measurement and candidate selection, followed by a graph matching module for geometry verification. On the system side, we adopt a centralized architecture to enable collaborative scanning. Each agent reconstructs a part of the scene, and the combination is activated when the overlaps are found using room-level LCD, which is performed on the server. Extensive comparisons demonstrate the superiority of the semantic-aware room-level LCD over traditional image-based LCD. Live demo on the real-world building-scale scenes shows the feasibility of our method with robust, collaborative, and real-time performance.
Latex Bibtex Citation:
@ARTICLE{9286413,
author={T. {Zheng} and G. {Zhang} and L. {Han} and L. {Xu} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Building Fusion: Semantic-aware Structural Building-scale 3D Reconstruction},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.3042881}}

L. Han, S. Gu, D. Zhong, S. Quan and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
High-quality reconstruction of 3D geometry and texture plays a vital role in providing immersive perception of the real world. Additionally, online computation enables the practical usage of 3D reconstruction for interaction. We present an RGBD-based globally-consistent dense 3D reconstruction approach, accompanying high-resolution (< 1 cm) geometric reconstruction and high-quality (the spatial resolution of the RGB image) texture mapping, both of which work online using the CPU computing of a portable device merely. For geometric reconstruction, we introduce a sparse voxel sampling scheme employing the continuous nature of surfaces in 3D space, reducing more than 95% of the computational burden compared with conventional volumetric fusion approaches. For online texture mapping, we propose a simplified incremental MRF solver, which utilizes previous optimization results for faster convergence, and an efficient reference-based color adjustment scheme for texture optimization. Quantitative and qualitative experiments demonstrate that our online scheme achieves a more realistic visualization of the environment with more abundant details, while taking more compact memory consumption and much lower computational complexity than existing solutions.
Latex Bibtex Citation:
@ARTICLE{9184935,
author={L. {Han} and S. {Gu} and D. {Zhong} and s. {quan} and L. {FANG}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Real-time Globally Consistent Dense 3D Reconstruction with Online Texturing},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.3021023}}

M. Ji, J. Zhang, Q. Dai and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since sparser sampling is always more favorable inpractice. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for thecase with larger baseline angle that worsens the photo-consistency check. As another line of solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and 'inaccuracy' problems induced by very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and the state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting.
Latex Bibtex Citation:
@ARTICLE{ji2020surfacenet_plus,
title={SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis},
author={M. {Ji} and J. {Zhang} and Q. {Dai} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2020},
volume={},
number={},
pages={1-1},
}

D. Zhong, L. Han and L. Fang,
Proc. of The 27th ACM International Conference on Multimedia (MM '19).
We present a practical fast, globally consistent and robust dense 3D reconstruction system, iDFusion, by exploring the joint benefit of both the visual (RGB-D) solution and inertial measurement unit (IMU). A global optimization considering all the previous states is adopted to maintain high localization accuracy and global consistency, yet its complexity of being linear to the number of all previous camera/IMU observations seriously impedes real-time implementation. We show that the global optimization can be solved efficiently at the complexity linear to the number of keyframes, and further realize a real-time dense 3D reconstruction system given the estimated camera states. Meanwhile, for the sake of robustness, we propose a novel loop-validity detector based on the estimated bias of the IMU state. By checking the consistency of camera movements, a false loop closure constraint introduces manifest inconsistency between the camera movements and IMU measurements. Experiments reveal that iDFusion owns superior reconstruction performance running in 25 fps on CPU computing of portable devices, under challenging yet practical scenarios including texture-less, motion blur, and repetitive contents.
Latex Bibtex Citation:
@inproceedings{10.1145/3343031.3351085, author = {Zhong, Dawei and Han, Lei and Fang, Lu}, title = {IDFusion: Globally Consistent Dense 3D Reconstruction from RGB-D and Inertial Measurements}, year = {2019}, isbn = {9781450368896}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3343031.3351085}, doi = {10.1145/3343031.3351085}, booktitle = {Proceedings of the 27th ACM International Conference on Multimedia}, pages = {962–970}, numpages = {9}, keywords = {loop closure, visual-imu global optimization, 3d reconstruction, real-time slam}, location = {Nice, France}, series = {MM '19} }

M. Ji, J. Gall, H. Zheng, Y. Liu and L. Fang,
Proc. of IEEE International Conference on Computer Vision (ICCV), Oct. 2017.
This paper proposes an end-to-end learning framework for multiview stereopsis. We term the network SurfaceNet. It takes a set of images and their corresponding camera parameters as input and directly infers the 3D model. The key advantage of the framework is that both photo-consistency as well geometric relations of the surface structure can be directly learned for the purpose of multiview stereopsis in an end-to-end fashion. SurfaceNet is a fully 3D convolutional network which is achieved by encoding the camera parameters together with the images in a 3D voxel representation. We evaluate SurfaceNet on the large-scale DTU benchmark.
Latex Bibtex Citation:
@INPROCEEDINGS{8237515, author={M. {Ji} and J. {Gall} and H. {Zheng} and Y. {Liu} and L. {Fang}}, booktitle={2017 IEEE International Conference on Computer Vision (ICCV)}, title={SurfaceNet: An End-to-End 3D Neural Network for Multiview Stereopsis}, year={2017}, volume={}, number={}, pages={2326-2334}, doi={10.1109/ICCV.2017.253}}