
2025
Z. Wang, Y. Peng, L. Fang, L. Gao
Optica, 2025
Optical imaging has traditionally relied on hardware to fulfill its imaging function, producing output measures that mimic the original objects. Developed separately, digital algorithms enhance or analyze these visual representations, rather than being integral to the imaging process. The emergence of computational optical imaging has blurred the boundary between hardware and algorithm, incorporating computation in silico as an essential step in producing the final image. It provides additional degrees of freedom in system design and enables unconventional capabilities and greater efficiency. This mini-review surveys various perspectives of such interactions between physical and digital layers. It discusses the representative works where dedicated algorithms join the specialized imaging modalities or pipelines to achieve images of unprecedented quality. It also examines the converse scenarios where hardware, such as optical elements and sensors, is engineered to perform image processing, partially or fully replacing computer-based counterparts. Finally, the review highlights the emerging field of end-to-end optimization, where optics and algorithms are co-designed using differentiable models and task-specific loss functions. Together, these advancements provide an overview of the current landscape of computational optical imaging, delineating significant progress while uncovering diverse directions and potential in this rapidly evolving field.
Latex Bibtex Citation:
2024

Z. Xue, T. Zhou, Z. Xu, S. Yu, Q. Dai, and L. Fang,
Nature, 2024.
Optical computing promises to improve the speed and energy efficiency of machine learning applications1–6. However, current approaches to efficiently train these models are limited by in silico emulation on digital computers. Here we develop a method called fully forward mode (FFM) learning, which implements the compute- intensive training process on the physical system. The majority of the machine learning operations are thus efficiently conducted in parallel on site, alleviating numerical modelling constraints. In free-space and integrated photonics, we experimentally demonstrate optical systems with state-of-the-art performances for a given network size. FFM learning shows training the deepest optical neural networks with millions of parameters achieves accuracy equivalent to the ideal model. It supports all-optical focusing through scattering media with a resolution of the diffraction limit; it can also image in parallel the objects hidden outside the direct line of sight at over a kilohertz frame rate and can conduct all-optical processing with light intensity as weak as subphoton per pixel (5.40 × 1018- operations-per-second- per-watt energy efficiency) at room temperature. Furthermore, we prove that FFM learning can automatically search non-Hermitian exceptional points without an analytical model. FFM learning not only facilitates orders-of-magnitude-faster learning processes, but can also advance applied and theoretical fields such as deep neural networks, ultrasensitive perception and topological photonics.
Latex Bibtex Citation:
Xue, Z., Zhou, T., Xu, Z. et al. Fully forward mode training for optical neural networks. Nature 632, 280–286 (2024). https://doi.org/10.1038/s41586-024-07687-4

Z. Xu, T. Zhou, M. Ma, C. Deng, Q. Dai, and L. Fang,
Science, 2024.
Latex Bibtex Citation:
@article{xu2024large,
title={Large-scale photonic chiplet Taichi empowers 160-TOPS/W artificial general intelligence},
author={Xu, Zhihao and Zhou, Tiankuang and Ma, Muzhou and Deng, ChenChen and Dai, Qionghai and Fang, Lu},
journal={Science},
volume={384},
number={6692},
pages={202--209},
year={2024},
publisher={American Association for the Advancement of Science}
} 
Y. Guo, Y. Hao, S. Wan, H. Zhang, L. Zhu, Y. Zhang, J. Wu, Q. Dai, and L. Fang,
Nature Photonics, 2024.
Turbulence is a complex and chaotic state of fuid motion. Atmospheric turbulence within the Earth’s atmosphere poses fundamental challenges for applications such as remote sensing, free-space optical communications and astronomical observation due to its rapid evolution across temporal and spatial scales. Conventional methods for studying atmospheric turbulence face hurdles in capturing the wide-feld distribution of turbulence due to its transparency and anisoplanatism. Here we develop a light-feld-based plug-and-play wide-feld wavefront sensor (WWS), facilitating the direct observation of atmospheric turbulence over 1,100 arcsec at 30 Hz. The experimental measurements agreed with the von Kármán turbulence model, further verifed using a diferential image motion monitor. Attached to an 80 cm telescope, our WWS enables clear turbulence profling of three layers below an altitude of 750 m and high-resolution aberration-corrected imaging without additional deformable mirrors. The WWS also enables prediction of the evolution of turbulence dynamics within 33 ms using a convolutional recurrent neural network with wide-feld measurements, leading to more accurate pre-compensation of turbulence-induced errors during free-space optical communication. Wide-feld sensing of dynamic turbulence wavefronts provides new opportunities for studying the evolution of turbulence in the broad feld of atmospheric optics.
Latex Bibtex Citation:
@article{guo2024direct,
title={Direct observation of atmospheric turbulence with a video-rate wide-field wavefront sensor},
author={Guo, Yuduo and Hao, Yuhan and Wan, Sen and Zhang, Hao and Zhu, Laiyu and Zhang, Yi and Wu, Jiamin and Dai, Qionghai and Fang, Lu},
journal={Nature Photonics},
pages={1--9},
year={2024},
publisher={Nature Publishing Group UK London}
}
T. Yan, T. Zhou, Y. Guo, Y. Zhao, G. Shao, J. Wu, R. Huang, Q. Dai, and L. Fang,
Science Advances, 2024.
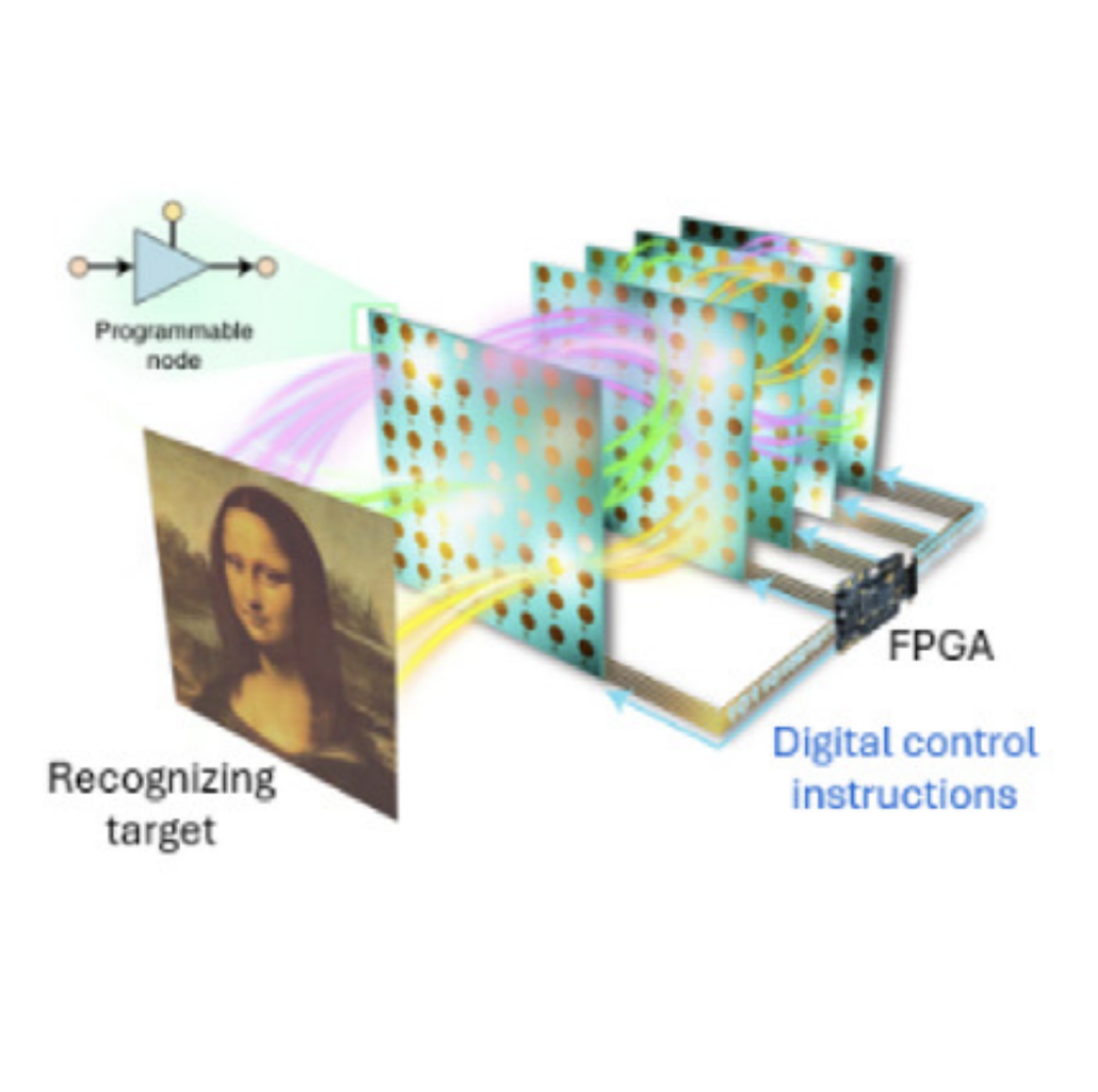
Three-dimensional (3D) perception is vital to drive mobile robotics’ progress toward intelligence. However, state-of-the-art 3D perception solutions require complicated postprocessing or point-by-point scanning, sufferingcomputational burden, latency of tens of milliseconds, and additional power consumption. Here, we propose aparallel all-optical computational chipset 3D perception architecture (Aop3D) with nanowatt power and lightspeed. The 3D perception is executed during the light propagation over the passive chipset, and the capturedlight intensity distribution provides a direct reflection of the depth map, eliminating the need for extensive post-processing. The prototype system of Aop3D is tested in various scenarios and deployed to a mobile robot, demon-strating unprecedented performance in distance detection and obstacle avoidance. Moreover, Aop3D works at aframe rate of 600 hertz and a power consumption of 33.3 nanowatts per meta-pixel experimentally. Our work ispromising toward next-generation direct 3D perception techniques with light speed and high energy efficiency.
Latex Bibtex Citation:
@article{yan2024nanowatt,
title={Nanowatt all-optical 3D perception for mobile robotics},
author={Yan, Tao and Zhou, Tiankuang and Guo, Yanchen and Zhao, Yun and Shao, Guocheng and Wu, Jiamin and Huang, Ruqi and Dai, Qionghai and Fang, Lu},
journal={Science Advances},
volume={10},
number={27},
pages={eadn2031},
year={2024},
publisher={American Association for the Advancement of Science}
}
W. Wu, T. Zhou, and L. Fang,
OSA Optica, 2024.
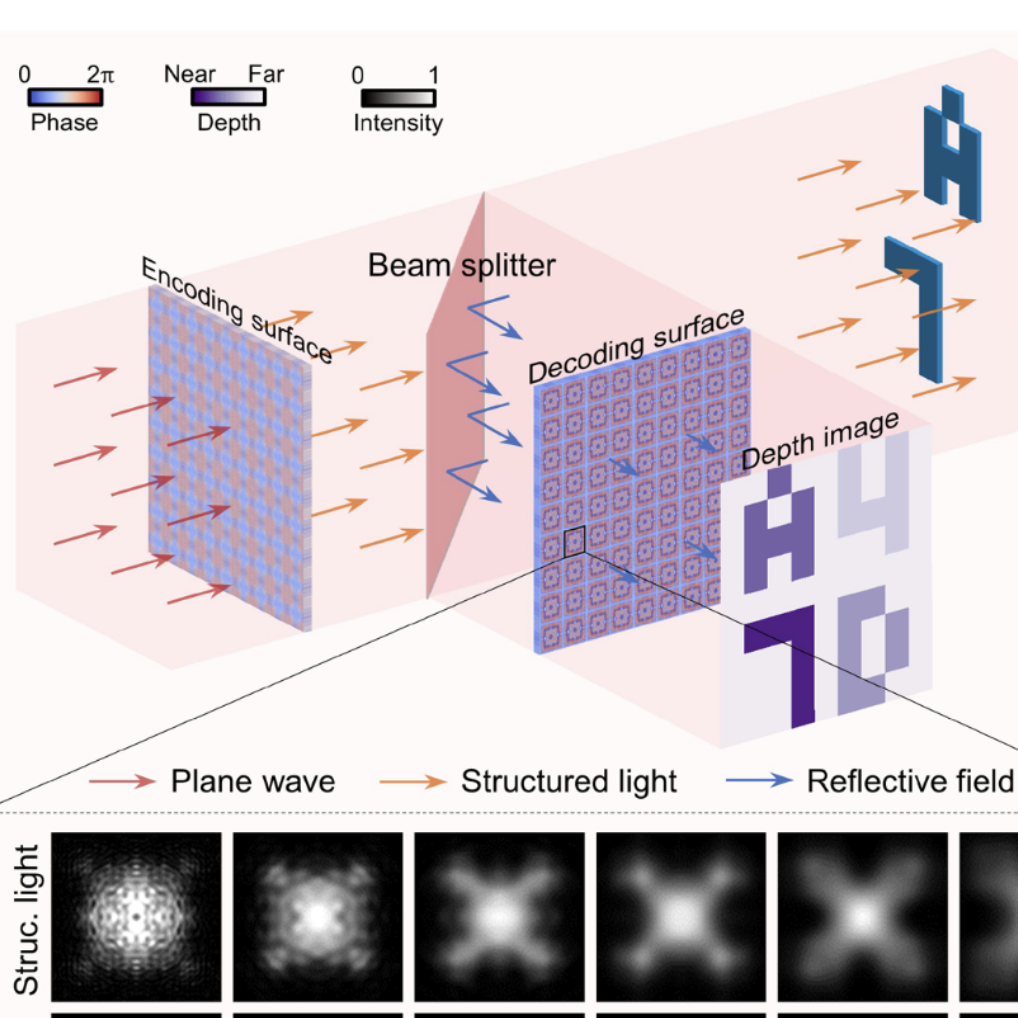
Image processing, transmission, and reconstruction constitute a major proportion of information technology. The rapid expansion of ubiquitous edge devices and data centers has led to substantial demands on the bandwidth and efficiency of image processing, transmission, and reconstruction. The frequent conversion of serial signals between the optical and electrical domains, coupled with the gradual saturation of electronic processors, has become the bottleneck of end-toend machine vision. Here, we present an optical parallel computational array chip (OPCA chip) for end-to-end processing, transmission, and reconstruction of optical intensity images. By proposing constructive and destructive computing modes on the large-bandwidth resonant optical channels, a parallel computational model is constructed to implement end-to-end optical neural network computing. The OPCA chip features a measured response time of 6 ns and an optical bandwidth of at least 160 nm. Optical image processing can be efficiently executed with minimal energy consumption and latency, liberated from the need for frequent optical–electronic and analog–digital conversions. The proposed optical computational sensor opens the door to extremely high-speed processing, transmission, and reconstruction of visible contents with nanoseconds response time and terahertz bandwidth.
Latex Bibtex Citation:
@article{wu2024parallel,
title={Parallel photonic chip for nanosecond end-to-end image processing, transmission, and reconstruction},
author={Wu, Wei and Zhou, Tiankuang and Fang, Lu},
journal={Optica},
volume={11},
number={6},
pages={831--837},
year={2024},
publisher={Optica Publishing Group}
}
Y. Cheng, J. Zhang, T. Zhou, Y. Wang, Z. Xu, X. Yuan, and L. Fang,
Light: Science & Applications, 2024.
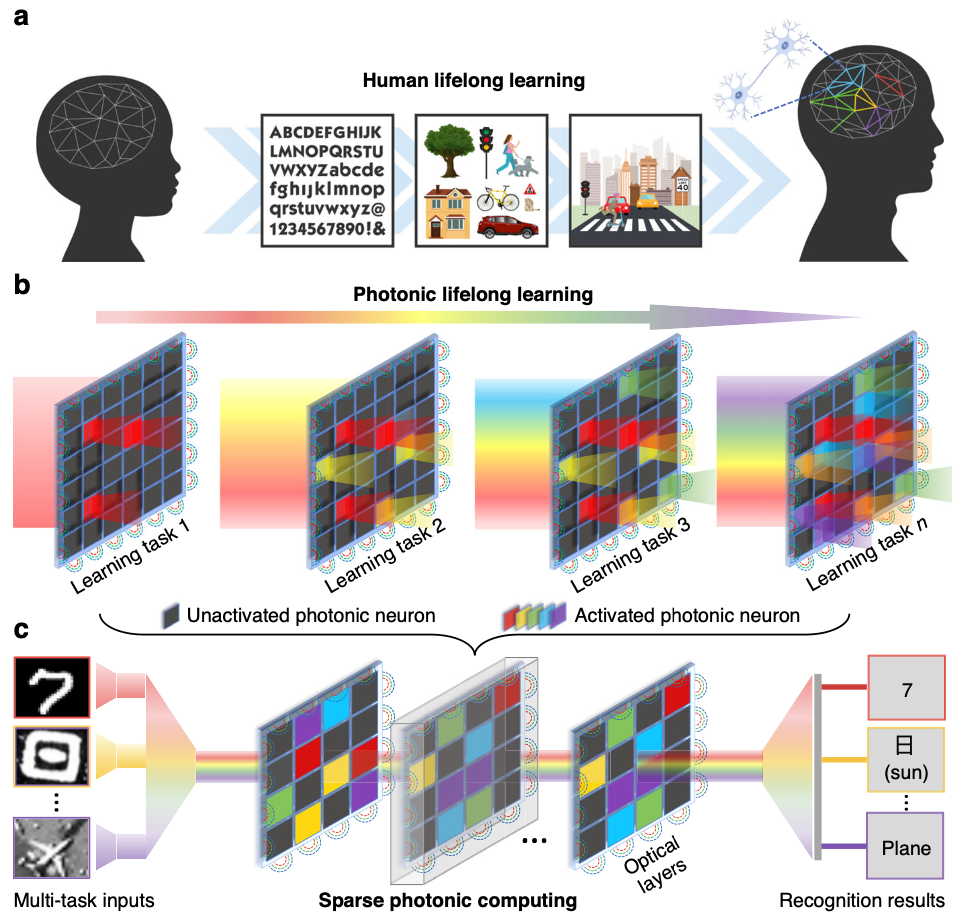
Scalable, high-capacity, and low-power computing architecture is the primary assurance for increasingly manifold and large-scale machine learning tasks. Traditional electronic artificial agents by conventional power-hungry processors have faced the issues of energy and scaling walls, hindering them from the sustainable performance improvement and iterative multi-task learning. Referring to another modality of light, photonic computing has been progressively applied in high-efficient neuromorphic systems. Here, we innovate a reconfigurable lifelong-learning optical neural network (L2ONN), for highly-integrated tens-of-task machine intelligence with elaborated algorithm-hardware co-design. Benefiting from the inherent sparsity and parallelism in massive photonic connections, L2ONN learns each single task by adaptively activating sparse photonic neuron connections in the coherent light field, while incrementally acquiring expertise on various tasks by gradually enlarging the activation. The multi-task optical features are parallelly processed by multi-spectrum representations allocated with different wavelengths. Extensive evaluations on free-space and on-chip architectures confirm that for the first time, L2ONN avoided the catastrophic forgetting issue of photonic computing, owning versatile skills on challenging tens-of-tasks (vision classification, voice recognition, medical diagnosis, etc.) with a single model. Particularly, L2ONN achieves more than an order of magnitude higher efficiency than the representative electronic artificial neural networks, and 14× larger capacity than existing optical neural networks while maintaining competitive performance on each individual task. The proposed photonic neuromorphic architecture points out a new form of lifelong learning scheme, permitting terminal/edge AI systems with light-speed efficiency and unprecedented scalability.
Latex Bibtex Citation:
@article{cheng2024photonic,
title={Photonic neuromorphic architecture for tens-of-task lifelong learning},
author={Cheng, Yuan and Zhang, Jianing and Zhou, Tiankuang and Wang, Yuyan and Xu, Zhihao and Yuan, Xiaoyun and Fang, Lu},
journal={Light: Science \& Applications},
volume={13},
number={1},
pages={56},
year={2024},
publisher={Nature Publishing Group UK London}
}
T. Ma, B. Bai, H. Lin, H. Wang, Y. Wang, L. Luo, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2024.
Visual grounding refers to the process of associating
natural language expressions with corresponding regions
within an image. Existing benchmarks for visual grounding
primarily operate within small-scale scenes with a few objects. Nevertheless, recent advances in imaging technology
have enabled the acquisition of gigapixel-level images, providing high-resolution details in large-scale scenes containing numerous objects. To bridge this gap between imaging
and computer vision benchmarks and make grounding more
practically valuable, we introduce a novel dataset, named
GigaGrounding, designed to challenge visual grounding
models in gigapixel-level large-scale scenes. We extensively
analyze and compare the dataset with existing benchmarks,
demonstrating that GigaGrounding presents unique challenges such as large-scale scene understanding, gigapixel-level resolution, significant variations in object scales, and
the “multi-hop expressions”. Furthermore, we introduced
a simple yet effective grounding approach, which employs
a “glance-to-zoom-in” paradigm and exhibits enhanced
capabilities for addressing the GigaGrounding task. The dataset is available at www.gigavision.ai.
Latex Bibtex Citation:
H. Lin, C. Wei, Y. Guo, L. He, Y. Zhao, S. Li, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2024.
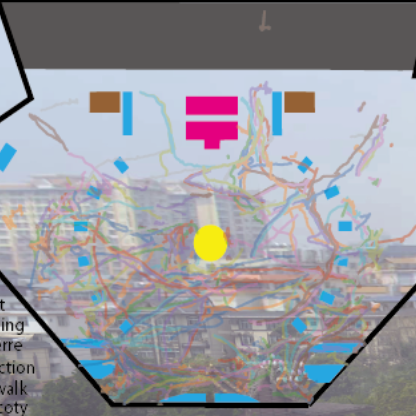
Pedestrian trajectory prediction is a well-established task with significant recent advancements. However, existing datasets are unable to fulfill the demand for studying minute-level long-term trajectory prediction, mainly due to the lack of high-resolution trajectory observation in the wide field of view (FoV). To bridge this gap, we introduce a novel dataset named GigaTraj, featuring videos capturing a wide FoV with ∼4 × 104 m2 and high-resolution imagery at the gigapixel level. Furthermore, GigaTraj includes comprehensive annotations such as bounding boxes, identity associations, world coordinates, group/interaction relationships, and scene semantics. Leveraging these multimodal annotations, we evaluate and validate the state-of-the-art approaches for minute-level long-term trajectory prediction in large-scale scenes. Extensive experiments and analyses have revealed that long-term prediction for pedestrian trajectories presents numerous challenges, indicating a vital new direction for trajectory research. The dataset is available at www.gigavision.ai.
Latex Bibtex Citation:
H. Ying, Y. Yin, J. Zhang, F. Wang, T. Yu, R. Huang, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2024.
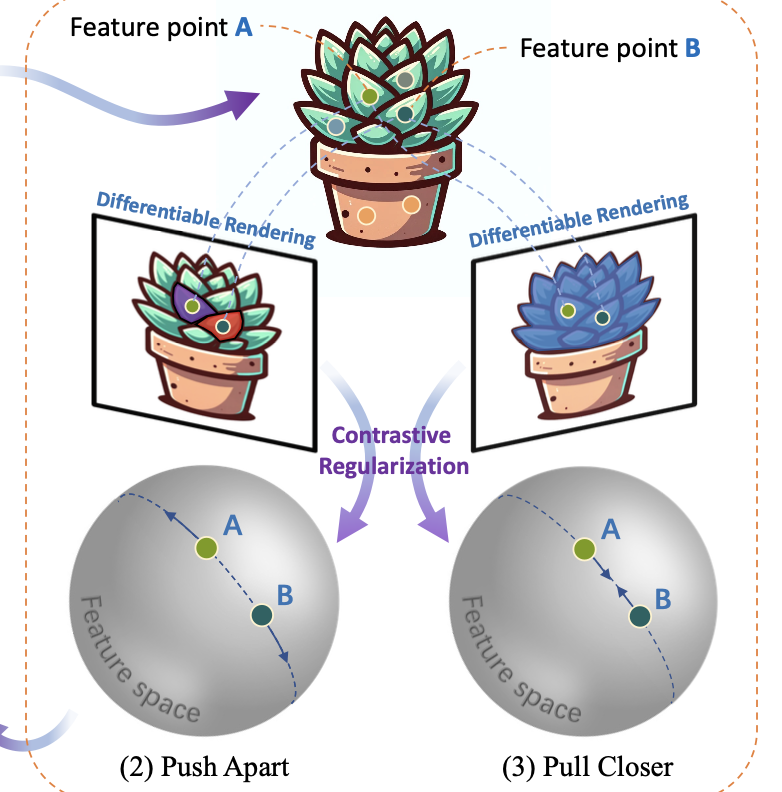
Towards holistic understanding of 3D scenes, a general 3D segmentation method is needed that can segment diverse objects without restrictions on object quantity or categories, while also reflecting the inherent hierarchical structure. To achieve this, we propose OmniSeg3D, an omniversal segmentation method aims for segmenting anything in 3D all at once. The key insight is to lift multi-view inconsistent 2D segmentations into a consistent 3D feature field through a hierarchical contrastive learning framework, which is accomplished by two steps. Firstly, we design a novel hierarchical representation based on category-agnostic 2D segmentations to model the multi-level relationship among pixels. Secondly, image features rendered from the 3D feature field are clustered at different levels, which can be further drawn closer or pushed apart according to the hierarchical relationship between different levels. In tackling the challenges posed by inconsistent 2D segmentations, this framework yields a global consistent 3D feature field, which further enables hierarchical segmentation, multi-object selection, and global discretization. Extensive experiments demonstrate the effectiveness of our method on high-quality 3D segmentation and accurate hierarchical structure understanding. A graphical user interface further facilitates flexible interaction for omniversal 3D segmentation.
Latex Bibtex Citation:
@misc{ying2023omniseg3d,
title={OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning},
author={Haiyang Ying and Yixuan Yin and Jinzhi Zhang and Fan Wang and Tao Yu and Ruqi Huang and Lu Fang},
year={2023},
eprint={2311.11666},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Z. Yao, S. Liu, X. Yuan, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2024.
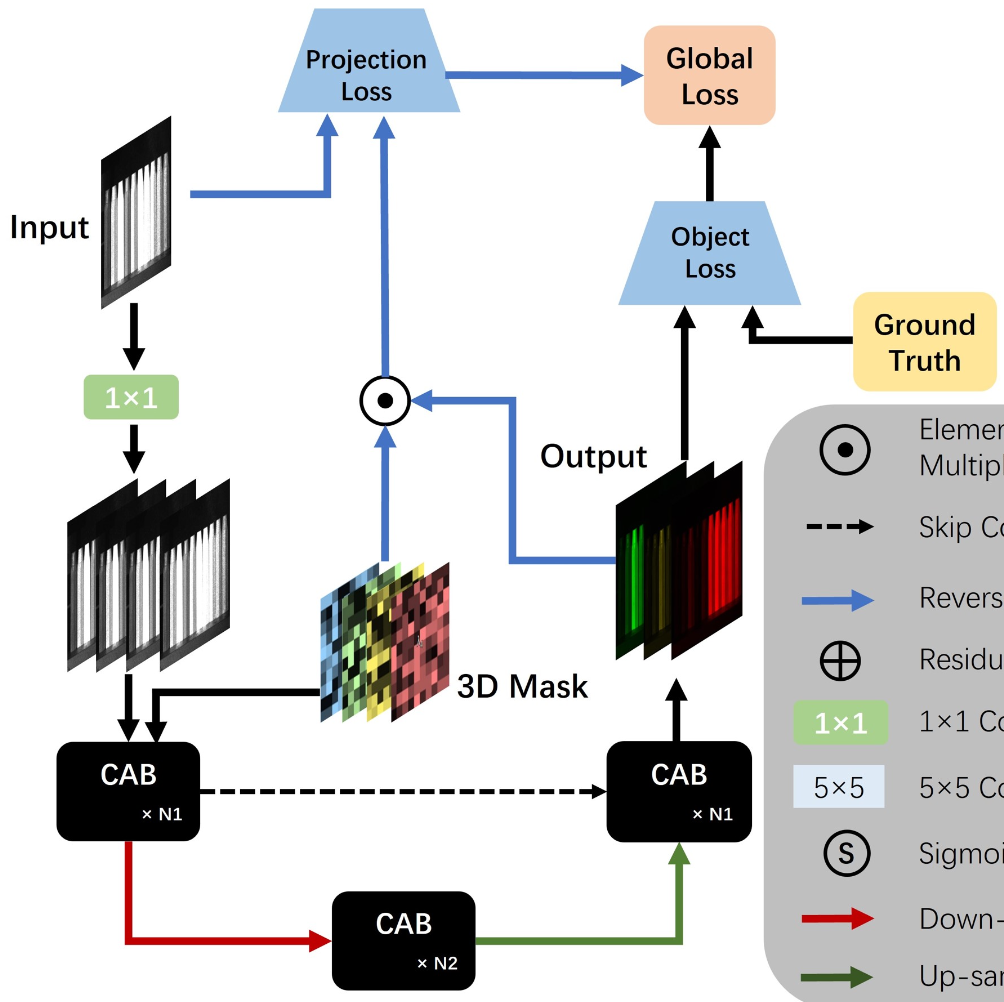
Compressive spectral image reconstruction is a critical method for acquiring images with high spatial and spectral resolution. Current advanced methods, which involve designing deeper networks or adding more self-attention modules, are limited by the scope of attention modules and the irrelevance of attentions across different dimensions. This leads to difficulties in capturing non-local mutation features in the spatial-spectral domain and results in a significant parameter increase but only limited performance improvement. To address these issues, we propose SPECAT, a SPatial-spEctral Cumulative-Attention Transformer designed for high-resolution hyperspectral image reconstruction. SPECAT utilizes Cumulative-Attention Blocks (CABs) within an efficient hierarchical framework to extract features from non-local spatial-spectral details. Furthermore, it employs a projection-object Dual-domain Loss Function (DLF) to integrate the optical path constraint, a physical aspect often overlooked in current methodologies. Ultimately, SPECAT not only significantly enhances the reconstruction quality of spectral details but also breaks through the bottleneck of mutual restriction between the cost and accuracy in existing algorithms. Our experimental results demonstrate the superiority of SPECAT, achieving 40.3 dB in hyperspectral reconstruction benchmarks, outperforming the state-of-the-art (SOTA) algorithms by 1.2 dB while using only 5% of the network parameters and 10% of the computational cost. The code is available at https://github.com/THU-luvision/SPECAT.
Latex Bibtex Citation:

G. Wang, J. Zhang, F. Wang, R. Huang, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2024.
We propose XScale-NVS for high-fidelity cross-scale
novel view synthesis of real-world large-scale scenes. Existing representations based on explicit surface suffer from
discretization resolution or UV distortion, while implicit
volumetric representations lack scalability for large scenes
due to the dispersed weight distribution and surface ambiguity. In light of the above challenges, we introduce hash
featurized manifold, a novel hash-based featurization coupled with a deferred neural rendering framework. This approach fully unlocks the expressivity of the representation
by explicitly concentrating the hash entries on the 2D manifold, thus effectively representing highly detailed contents
independent of the discretization resolution. We also introduce a novel dataset, namely GigaNVS, to benchmark
cross-scale, high-resolution novel view synthesis of real-world large-scale scenes. Our method significantly outper-
forms competing baselines on various real-world scenes,
yielding an average LPIPS that is ∼ 40% lower than prior
state-of-the-art on the challenging GigaNVS benchmark.
Please see our project page at: xscalenvs.github.io.
Latex Bibtex Citation:
@misc{wang2024xscalenvs,
title={XScale-NVS: Cross-Scale Novel View Synthesis with Hash Featurized Manifold},
author={Guangyu Wang and Jinzhi Zhang and Fan Wang and Ruqi Huang and Lu Fang},
year={2024},
eprint={2403.19517},
archivePrefix={arXiv},
primaryClass={cs.CV} }
2023

Y. Chen, M. Nazhamati, H. Xu, Y. Meng, T. Zhou, G. Li, J. Fan, Q. Wei, J. Wu, F. Qiao, L. Fang, and Q. Dai,
Nature, 2023.
Photonic computing enables faster and more energy-efficient processing of vision
data. However, experimental superiority of deployable systems remains a challenge
because of complicated optical nonlinearities, considerable power consumption of analog-to-digital converters (ADCs) for downstream digital processing and
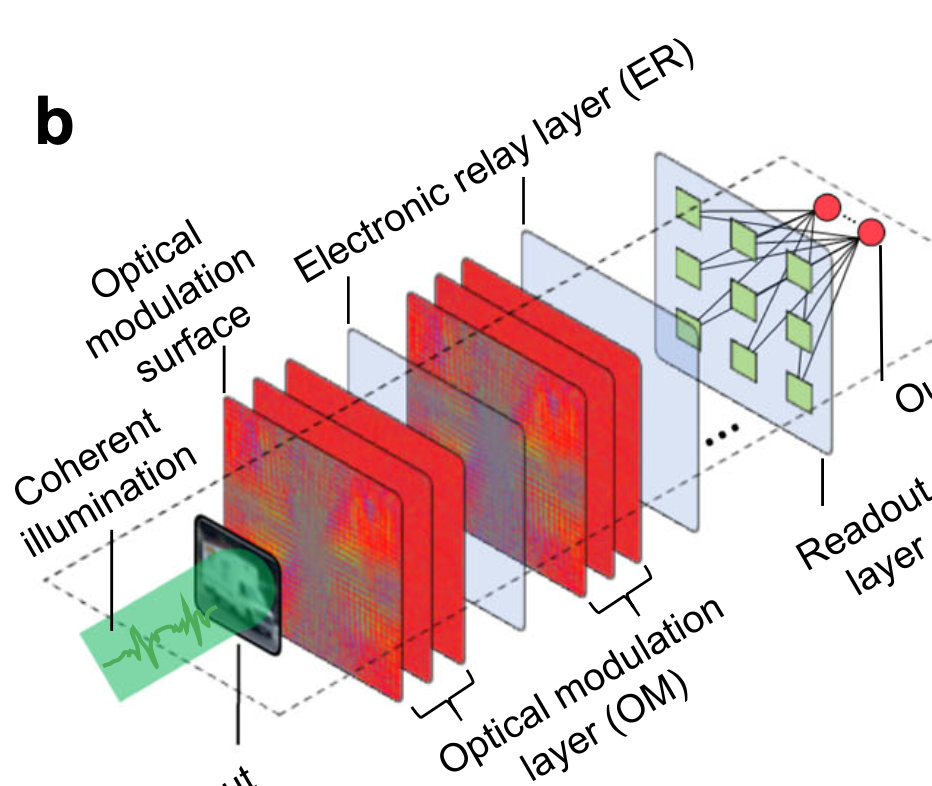
vulnerability to noises and system errors. Here we propose an all-analog chip
combining electronic and light computing (ACCEL). It has a systemic energy efficiency
of 74.8 peta-operations per second per watt and a computing speed of 4.6 peta-
operations per second (more than 99% implemented by optics), corresponding to
more than three and one order of magnitude higher than state-of-the-art computing
processors, respectively. After applying diffractive optical computing as an optical
encoder for feature extraction, the light-induced photocurrents are directly used for
further calculation in an integrated analog computing chip without the requirement
of analog-to-digital converters, leading to a low computing latency of 72 ns for each
frame. With joint optimizations of optoelectronic computing and adaptive training,
ACCEL achieves competitive classification accuracies of 85.5%, 82.0% and 92.6%,
respectively, for Fashion-MNIST, 3-class ImageNet classification and time-lapse video
recognition task experimentally, while showing superior system robustness in low-
light conditions (0.14 fJ μm−2 each frame). ACCEL can be used across a broad range of
applications such as wearable devices, autonomous driving and industrial inspections.
Latex Bibtex Citation:
@article{chen2023all,
title={All-analog photoelectronic chip for high-speed vision tasks},
author={Chen, Yitong and Nazhamaiti, Maimaiti and Xu, Han and Meng, Yao and Zhou, Tiankuang and Li, Guangpu and Fan, Jingtao and Wei, Qi and Wu, Jiamin and Qiao, Fei and others},
journal={Nature},
pages={1--10},
year={2023},
publisher={Nature Publishing Group UK London}
}
X. Yuan, Y. Wang, Z. Xu, T. Zhou, and L. Fang,
Nature Communications, 2023.
Optoelectronic neural networks (ONN) are a promising avenue in AI com- puting due to their potential for parallelization, power efficiency, and speed. Diffractive neural networks, which process information by propagating encoded light through trained optical elements, have garnered interest. However, training large-scale diffractive networks faces challenges due to the computational and memory costs of optical diffraction modeling. Here, we present DANTE, a dual-neuron optical-artificial learning architecture. Optical neurons model the optical diffraction, while artificial neurons approximate the intensive optical-diffraction computations with lightweight functions. DANTE also improves convergence by employing iterative global artificial-learning steps and local optical-learning steps. In simulation experiments, DANTE successfully trains large-scale ONNs with 150 million neurons on ImageNet, previously unattainable, and accelerates training speeds significantly on the CIFAR-10 benchmark compared to single-neuron learning. In physical experi- ments, we develop a two-layer ONN system based on DANTE, which can effectively extract features to improve the classification of natural images.
Latex Bibtex Citation:
@article{yuan2023training,
title={Training large-scale optoelectronic neural networks with dual-neuron optical-artificial learning},
author={Yuan, Xiaoyun and Wang, Yong and Xu, Zhihao and Zhou, Tiankuang and Fang, Lu},
journal={Nature Communications},
volume={14},
number={1},
pages={7110},
year={2023},
publisher={Nature Publishing Group UK London}
}
T. Zhou, W. Wu, J. Zhang, S. Yu, and L. Fang,
Science Advances, 2023.
Ultrafast dynamic machine vision in the optical domain can provide unprecedented perspectives for high-performance computing. However, owing to the limited degrees of freedom, existing photonic computing approaches rely on the memory’s slow read/write operations to implement dynamic processing. Here, we propose a spatiotemporal photonic computing architecture to match the highly parallel spatial computing with high-speed temporal computing and achieve a three-dimensional spatiotemporal plane. A unified training framework is devised to optimize the physical system and the network model. The photonic processing speed of the benchmark video dataset is increased by 40-fold on a space-multiplexed system with 35-fold fewer parameters. A wavelength-multiplexed system realizes all-optical nonlinear computing of dynamic light field with a frame time of 3.57 nanoseconds. The proposed architecture paves the way for ultrafast advanced machine vision free from the limits of memory wall and will find applications in unmanned systems, autonomous driving, ultrafast science, etc.
Latex Bibtex Citation:
@article{zhou2023ultrafast,
title={Ultrafast dynamic machine vision with spatiotemporal photonic computing},
author={Zhou, Tiankuang and Wu, Wei and Zhang, Jinzhi and Yu, Shaoliang and Fang, Lu},
journal={Science Advances},
volume={9},
number={23},
pages={eadg4391},
year={2023},
publisher={American Association for the Advancement of Science}
} 
Y. Chen, T. Zhou, J. Wu, H. Qiao, X. Lin, L. Fang, and Q. Dai,
Science Advances, 2023.
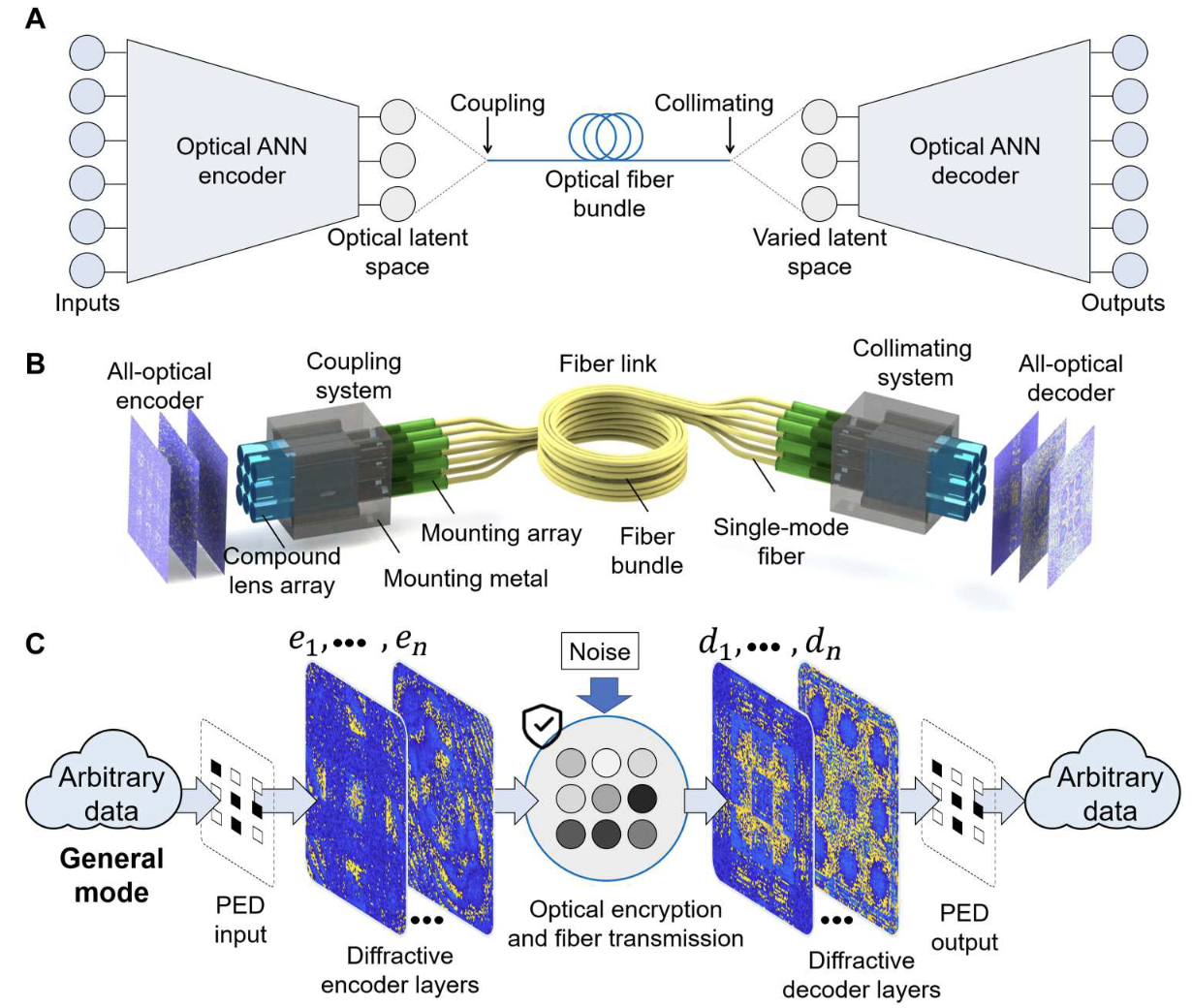
Following the explosive growth of global data, there is an ever-increasing demand for high-throughput processing in image transmission systems. However, existing methods mainly rely on electronic circuits, which severely limits the transmission throughput. Here, we propose an end-to-end all-optical variational autoencoder, named photonic encoder-decoder (PED), which maps the physical system of image transmission into an optical generative neural network. By modeling the transmission noises as the variation in optical latent space, the PED establishes a large-scale high-throughput unsupervised optical computing framework that integrates main computations in image transmission, including compression, encryption, and error correction to the optical domain. It reduces the system latency of computation by more than four orders of magnitude compared with the state-of-the-art devices and transmission error ratio by 57% than on-off keying. Our work points to the direction for a wide range of artificial intelligence–based physical system designs and next-generation communications.
Latex Bibtex Citation:
@article{chen2023photonic,
title={Photonic unsupervised learning variational autoencoder for high-throughput and low-latency image transmission},
author={Chen, Yitong and Zhou, Tiankuang and Wu, Jiamin and Qiao, Hui and Lin, Xing and Fang, Lu and Dai, Qionghai},
journal={Science Advances},
volume={9},
number={7},
pages={eadf8437},
year={2023},
publisher={American Association for the Advancement of Science}
} 
Y. Zhang, G. Zhang, X. Han, J. Wu, Z. Li, X. Li, G. Xiao, H. Xie, L. Fang, and Q. Dai,
Nature Methods, 2023.
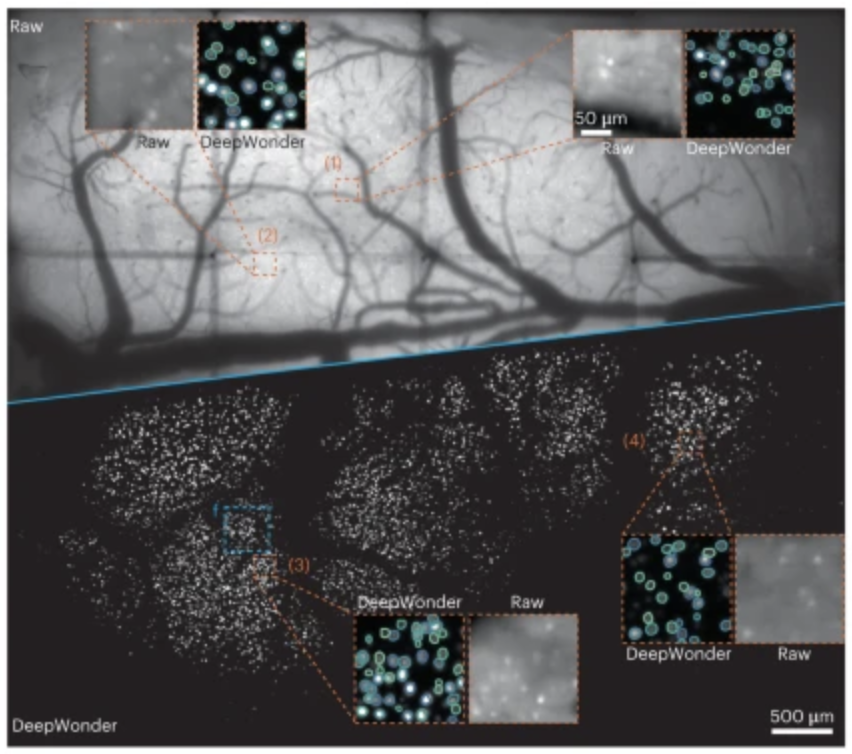
Widefeld microscopy can provide optical access to multi-millimeter felds of view and thousands of neurons in mammalian brains at video rate. However, tissue scattering and background contamination results in signal deterioration, making the extraction of neuronal activity challenging, laborious and time consuming. Here we present our deep-learning-based widefeld neuron fnder (DeepWonder), which is trained by simulated functional recordings and efectively works on experimental data to achieve high-fdelity neuronal extraction. Equipped with systematic background contribution priors, DeepWonder conducts neuronal inference with an order-of-magnitude-faster speed and improved accuracy compared with alternative approaches. DeepWonder removes background contaminations and is computationally efcient. Specifcally, DeepWonder accomplishes 50-fold signal-to-background ratio enhancement when processing terabytes-scale cortex-wide functional recordings, with over 14,000 neurons extracted in 17 h.
Latex Bibtex Citation:
@article{zhang2023rapid,
title={Rapid detection of neurons in widefield calcium imaging datasets after training with synthetic data},
author={Zhang, Yuanlong and Zhang, Guoxun and Han, Xiaofei and Wu, Jiamin and Li, Ziwei and Li, Xinyang and Xiao, Guihua and Xie, Hao and Fang, Lu and Dai, Qionghai},
journal={Nature Methods},
pages={1--8},
year={2023},
publisher={Nature Publishing Group US New York}
} 
Y. Zhang, X. Song, J. Xie, J. Hu, J. Chen, X. Li, H. Zhang, Q. Zhou, L. Yuan, C. Kong, Y. Shen, J. Wu, L. Fang, and Q. Dai,
Nature Communications, 2023.
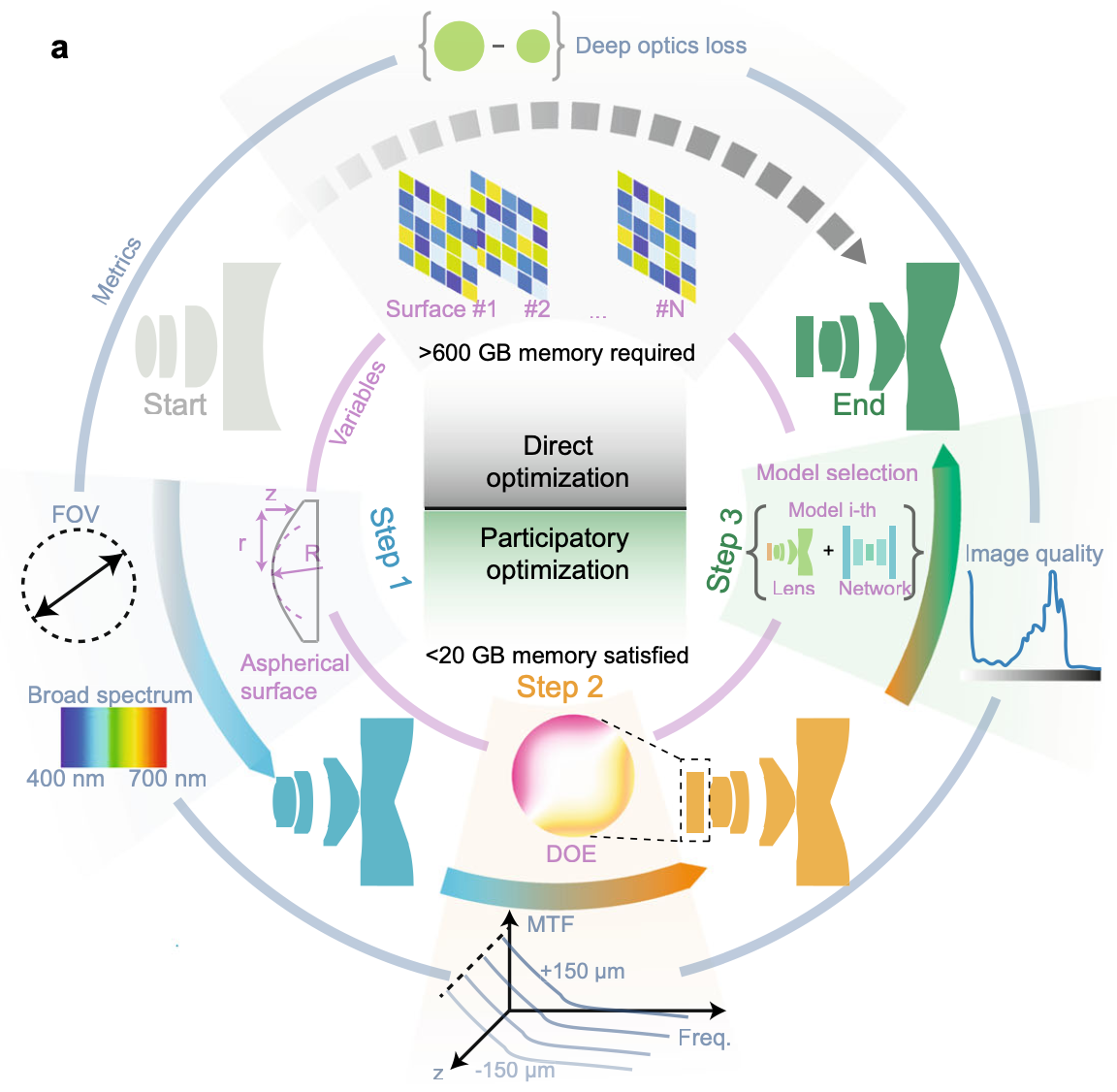
The optical microscope is customarily an instrument of substantial size and
expense but limited performance. Here we report an integrated microscope
that achieves optical performance beyond a commercial microscope with a 5×,
NA 0.1 objective but only at 0.15 cm^3 and 0.5 g, whose size is five orders of
magnitude smaller than that of a conventional microscope. To achieve this, a
progressive optimization pipeline is proposed which systematically optimizes
both aspherical lenses and diffractive optical elements with over 30 times
memory reduction compared to the end-to-end optimization. By designing a
simulation-supervision deep neural network for spatially varying deconvolu-
tion during optical design, we accomplish over 10 times improvement in the
depth-of-field compared to traditional microscopes with great generalization
in a wide variety of samples. To show the unique advantages, the integrated
microscope is equipped in a cell phone without any accessories for the
application of portable diagnostics. We believe our method provides a new
framework for the design of miniaturized high-performance imaging systems
by integrating aspherical optics, computational optics, and deep learning.
Latex Bibtex Citation:
@article{zhang2023large,
title={Large depth-of-field ultra-compact microscope by progressive optimization and deep learning},
author={Zhang, Yuanlong and Song, Xiaofei and Xie, Jiachen and Hu, Jing and Chen, Jiawei and Li, Xiang and Zhang, Haiyu and Zhou, Qiqun and Yuan, Lekang and Kong, Chui and others},
journal={Nature Communications},
volume={14},
number={1},
pages={4118},
year={2023},
publisher={Nature Publishing Group UK London}
}
G. Wang, J. Zhang, K. Zhang, R. Huang, and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Oct. 2023.
The rapid advances of high-performance sensation empowered gigapixel-level imaging/videography for large-scale scenes, yet the abundant details in gigapixel images were rarely valued in 3d reconstruction solutions. Bridging the gap between the sensation capacity and that of reconstruction requires to attack the large-baseline challenge imposed by the large-scale scenes, while utilizing the high-resolution details provided by the gigapixel images. This paper introduces GiganticNVS for gigapixel large-scale novel view synthesis (NVS). Existing NVS methods suffer from excessively blurred artifacts and fail on the full exploitation of image resolution, due to their inefficacy of recovering a faithful underlying geometry and the dependence on dense observations to accurately interpolate radiance. Our key insight is that, a highly-expressive implicit field with view-consistency is critical for synthesizing high-fidelity details from large-baseline observations. In light of this, we propose meta-deformed manifold, where meta refers to the locally defined surface manifold whose geometry and appearance are embedded into high-dimensional latent space. Technically, meta can be decoded as neural fields using an MLP (i.e., implicit representation). Upon this novel representation, multi-view geometric correspondence can be effectively enforced with featuremetric deformation and the reflectance field can be learned purely on the surface. Experimental results verify that the proposed method outperforms state-of-the-art methods both quantitatively and qualitatively, not only on the standard datasets containing complex real-world scenes with large baseline angles, but also on the challenging gigapixel-level ultra-large-scale benchmarks.
Latex Bibtex Citation:
@ARTICLE {10274871,
author = {G. Wang and J. Zhang and K. Zhang and R. Huang and L. Fang},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
title = {GiganticNVS: Gigapixel Large-scale Neural Rendering with Implicit Meta-deformed Manifold},
year = {2023},
volume = {},
number = {01},
issn = {1939-3539},
pages = {1-15},
doi = {10.1109/TPAMI.2023.3323069},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {oct}
}

X. Chen, S. Xu, X. Zou, T. Cao, D. Yeung and L. Fang,
Proc. of IEEE International Conference on Computer Vision (ICCV), 2023.
LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
Latex Bibtex Citation:
@inproceedings{chen2023svqnet,
title={SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation},
author={Chen, Xuechao and Xu, Shuangjie and Zou, Xiaoyi and Cao, Tongyi and Yeung, Dit-Yan and Fang, Lu},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={8569--8578},
year={2023}
}

H. Ying, B. Jiang, J. Zhang, D. Xu, T. Yu, Q. Dai, and L. Fang,
Proc. of IEEE International Conference on Computer Vision (ICCV), 2023.
This paper proposes a method for fast scene radiance field reconstruction with strong novel view synthesis perfor- mance and convenient scene editing functionality. The key idea is to fully utilize semantic parsing and primitive extrac- tion for constraining and accelerating the radiance field re- construction process. To fulfill this goal, a primitive aware hybrid rendering strategy was proposed to enjoy the best of both volumetric and primitive rendering. We further con- tribute a reconstruction pipeline conducts primitive parsing and radiance field learning iteratively for each input frame which successfully fuse semantic, primitive and radiance in- formation into a single framework. Extensive evaluations demonstrate the fast reconstruction ability, high rendering quality and convenient editing functionality of our method.
Latex Bibtex Citation:
@InProceedings{Ying_2023_ICCV, author = {Ying, Haiyang and Jiang, Baowei and Zhang, Jinzhi and Xu, Di and Yu, Tao and Dai, Qionghai and Fang, Lu}, title = {PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, month = {October}, year = {2023}, pages = {17706-17716} }
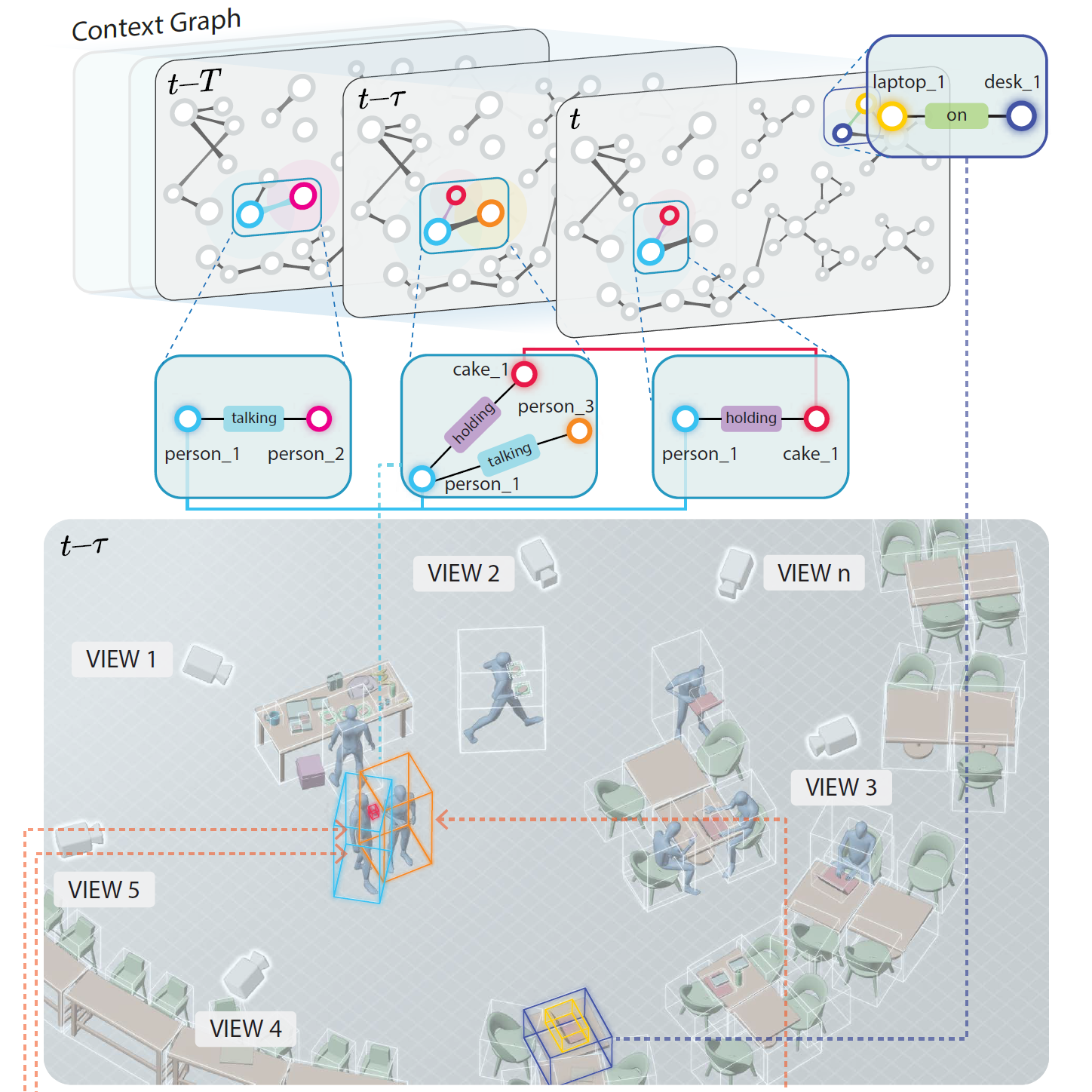
H. Lin, Z. Chen, J. Zhang, B. Bai, Y. Wang, R. Huang, and L. Fang,
Proc. of IEEE International Conference on Computer Vision (ICCV), 2023.
Understanding 4D scene context in real world has become urgently critical for deploying sophisticated AI systems. In this paper, we propose a brand new scene understanding paradigm called ''Context Graph Generation (CGG)'', aiming at abstracting holistic semantic information in the complicated 4D world. The CGG task capitalizes on the calibrated multiview videos of a dynamic scene, and targets at recovering semantic information (coordination, trajectories and relationships) of the presented objects in the form of spatio-temporal context graph in 4D space. We also present a benchmark 4D video dataset "RealGraph'', the first dataset tailored for the proposed CGG task. The raw data of RealGraph is composed of calibrated and synchronized multiview videos. We exclusively provide manual annotations including object 2D&3D bounding boxes, category labels and semantic relationships. We also make sure the annotated ID for every single object is temporally and spatially consistent. We propose the first CGG baseline algorithm, Multiview-based Context Graph Generation Network (MCGNet), to empirically investigate the legitimacy of CGG task on RealGraph dataset. We nevertheless reveal the great challenges behind this task and encourage the community to explore beyond our solution.
Latex Bibtex Citation:
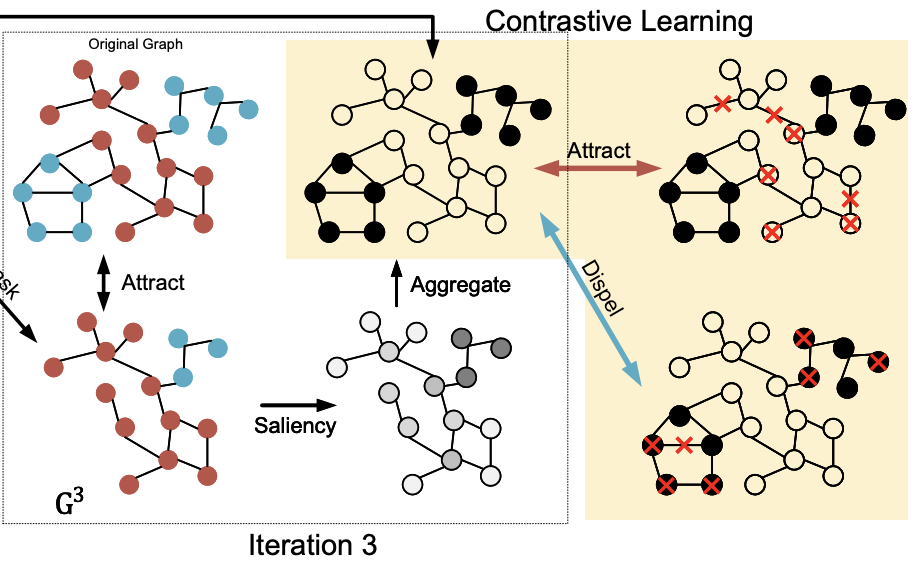
C. Wei, Y. Wang, B. Bai, K. Ni, D. Brady, and L. Fang,
Proceedings of the 40th International Conference on Machine Learning (ICML).
Graph augmentation plays a crucial role in achieving good generalization for contrastive graph selfsupervised learning. However, mainstream Graph Contrastive Learning (GCL) often favors random graph augmentations, by relying on random node dropout or edge perturbation on graphs. Random augmentations may inevitably lead to semantic information corruption during the training, and force the network to mistakenly focus on semantically irrelevant environmental background structures. To address these limitations and to improve generalization, we propose a novel selfsupervised learning framework for GCL, which can adaptively screen the semantic-related substructure in graphs by capitalizing on the proposed gradient-based Graph Contrastive Saliency (GCS). The goal is to identify the most semantically discriminative structures of a graph via contrastive learning, such that we can generate semantically meaningful augmentations by leveraging on saliency. Empirical evidence on 16 benchmark datasets demonstrates the exclusive merits of the GCS-based framework. We also provide rigorous theoretical justification for GCS’s robustness properties.
Latex Bibtex Citation:
@article{wei2023boosting,
title={Boosting Graph Contrastive Learning via Graph Contrastive Saliency},
author={Wei, Chunyu and Wang, Yu and Bai, Bing and Ni, Kai and Brady, David J and Fang, Lu},
year={2023}
} 
B. Jiang, B. Bai, H. Lin, Y. Wang, Y. Guo, and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2023.
Nowadays, privacy issue has become a top priority when training AI algorithms. Machine learning algorithms are expected to benefit our daily life, while personal information must also be carefully protected from exposure. Facial information is particularly sensitive in this regard. Multiple datasets containing facial information have been taken offline, and the community is actively seeking solutions to remedy the privacy issues. Existing methods for privacy preservation can be divided into blur-based and face replacement-based methods. Owing to the advantages of review convenience and good accessibility, blur-based based methods have become a dominant choice in practice. However, blur-based methods would inevitably introduce training artifacts harmful to the performance of downstream tasks. In this paper, we propose a novel De-artifact Blurring (DartBlur) privacy-preserving method, which capitalizes on a DNN architecture to generate blurred faces. DartBlur can effectively hide facial privacy information while detection artifacts are simultaneously suppressed. We have designed four training objectives that particularly aim to improve review convenience and maximize detection artifact suppression. We associate the algorithm with an adversarial training strategy with a second-order optimization pipeline. Experimental results demonstrate that DartBlur outperforms the existing face-replacement method from both perspectives of review convenience and accessibility, and also shows an exclusive advantage in suppressing the training artifact compared to traditional blur-based methods.
Latex Bibtex Citation:
@inproceedings{jiang2023dartblur,
title={DartBlur: Privacy Preservation With Detection Artifact Suppression},
author={Jiang, Baowei and Bai, Bing and Lin, Haozhe and Wang, Yu and Guo, Yuchen and Fang, Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={16479--16488},
year={2023}
} 
H. Wen, J. Huang, H. Cui, H. Lin, Y. Lai, L. Fang, and K. Li,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2023.
Image-based multi-person reconstruction in wide-field large scenes is critical for crowd analysis and security alert. However, existing methods cannot deal with large scenes containing hundreds of people, which encounter the challenges of large number of people, large variations in human scale, and complex spatial distribution. In this paper, we propose Crowd3D, the first framework to reconstruct the 3D poses, shapes and locations of hundreds of people with global consistency from a single large-scene image. The core of our approach is to convert the problem of complex crowd localization into pixel localization with the help of our newly defined concept, Human-scene Virtual Interaction Point (HVIP). To reconstruct the crowd with global consistency, we propose a progressive reconstruction network based on HVIP by pre-estimating a scene-level camera and a ground plane. To deal with a large number of persons and various human sizes, we also design an adaptive human-centric cropping scheme. Besides, we contribute a benchmark dataset, LargeCrowd, for crowd reconstruction in a large scene. Experimental results demonstrate the effectiveness of the proposed method.
Latex Bibtex Citation:
@inproceedings{wen2023crowd3d,
title={Crowd3D: Towards hundreds of people reconstruction from a single image},
author={Wen, Hao and Huang, Jing and Cui, Huili and Lin, Haozhe and Lai, Yu-Kun and Fang, Lu and Li, Kun},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8937--8946},
year={2023}
} 2022

J. Wu, Y. Guo, C. Deng, A. Zhang, H. Qiao, Z. Lu, J. Xie, L. Fang, and Q. Dai,
Nature (2022).
Planar digital image sensors facilitate broad applications in a wide range of areas and the number of pixels has scaled up rapidly in recent years2,6. However, the practical performance of imaging systems is fundamentally limited by spatially nonuniform optical aberrations originating from imperfect lenses or environmental disturbances. Here we propose an integrated scanning light-field imaging sensor, termed a meta-imaging sensor, to achieve high-speed aberration-corrected three-dimensional photography for universal applications without additional hardware modifications. Instead of directly detecting a two-dimensional intensity projection, the meta-imaging sensor captures extra-fine four-dimensional light-field distributions through a vibrating coded microlens array, enabling flexible and precise synthesis of complex-field-modulated images in post-processing. Using the sensor, we achieve high-performance photography up to a gigapixel with a single spherical lens without a data prior, leading to orders-of-magnitude reductions in system capacity and costs for optical imaging. Even in the presence of dynamic atmosphere turbulence, the meta-imaging sensor enables multisite aberration correction across 1,000 arcseconds on an 80-centimetre ground-based telescope without reducing the acquisition speed, paving the way for high-resolution synoptic sky surveys. Moreover, high-density accurate depth maps can be retrieved simultaneously, facilitating diverse applications from autonomous driving to industrial inspections.
Latex Bibtex Citation:

Z. Xu, X. Yuan, T. Zhou and L. Fang,
Light: Science & Applications, volume 11, Article number: 255 (2022).
Endowed with the superior computing speed and energy efficiency, optical neural networks (ONNs) have attracted ever-growing attention in recent years. Existing optical computing architectures are mainly single-channel due to the lack of advanced optical connection and interaction operators, solving simple tasks such as hand-written digit classification, saliency detection, etc. The limited computing capacity and scalability of single-channel ONNs restrict the optical implementation of advanced machine vision. Herein, we develop Monet: a multichannel optical neural network architecture for a universal multiple-input multiple-channel optical computing based on a novel projection-interference-prediction framework where the inter- and intra- channel connections are mapped to optical interference and diffraction. In our Monet, optical interference patterns are generated by projecting and interfering the multichannel inputs in a shared domain. These patterns encoding the correspondences together with feature embeddings are iteratively produced through the projection-interference process to predict the final output optically. For the first time, Monet validates that multichannel processing properties can be optically implemented with high-efficiency, enabling real-world intelligent multichannel-processing tasks solved via optical computing, including 3D/motion detections. Extensive experiments on different scenarios demonstrate the effectiveness of Monet in handling advanced machine vision tasks with comparative accuracy as the electronic counterparts yet achieving a ten-fold improvement in computing efficiency. For intelligent computing, the trends of dealing with real-world advanced tasks are irreversible. Breaking the capacity and scalability limitations of single-channel ONN and further exploring the multichannel processing potential of wave optics, we anticipate that the proposed technique will accelerate the development of more powerful optical AI as critical support for modern advanced machine vision.
Latex Bibtex Citation:
@article{xu2022multichannel,
title={A multichannel optical computing architecture for advanced machine vision},
author={Xu, Zhihao and Yuan, Xiaoyun and Zhou, Tiankuang and Fang, Lu},
journal={Light: Science \& Applications},
volume={11},
number={1},
pages={1--13},
year={2022},
publisher={Nature Publishing Group}
}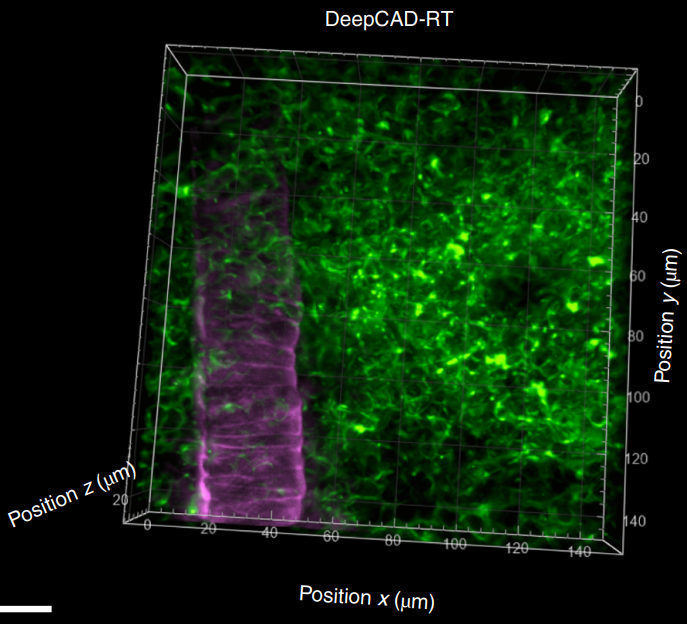
X. Li, Y. Li, Y. Zhou, J. Wu, Z. Zhao, J. Fan, F. Deng, Z. Wu, G. Xiao, J. He, Y. Zhang, G. Zhang, X. Hu, X. Chen, Y. Zhang, H. Qiao, H. Xie, Y. Li, H. Wang, L. Fang, and Q. Dai,
Nature Biotechnology, 2022: 1-11.
A fundamental challenge in fluorescence microscopy is the photon shot noise arising from the inevitable stochasticity of
photon detection. Noise increases measurement uncertainty and limits imaging resolution, speed and sensitivity. To achieve
high-sensitivity fluorescence imaging beyond the shot-noise limit, we present DeepCAD-RT, a self-supervised deep learning method for real-time noise suppression. Based on our previous framework DeepCAD, we reduced the number of network
parameters by 94%, memory consumption by 27-fold and processing time by a factor of 20, allowing real-time processing on
a two-photon microscope. A high imaging signal-to-noise ratio can be acquired with tenfold fewer photons than in standard
imaging approaches. We demonstrate the utility of DeepCAD-RT in a series of photon-limited experiments, including in vivo
calcium imaging of mice, zebrafish larva and fruit flies, recording of three-dimensional (3D) migration of neutrophils after acute
brain injury and imaging of 3D dynamics of cortical ATP release. DeepCAD-RT will facilitate the morphological and functional
interrogation of biological dynamics with a minimal photon budget.
Latex Bibtex Citation:
@article{li2022real,
title={Real-time denoising enables high-sensitivity fluorescence time-lapse imaging beyond the shot-noise limit},
author={Li, Xinyang and Li, Yixin and Zhou, Yiliang and Wu, Jiamin and Zhao, Zhifeng and Fan, Jiaqi and Deng, Fei and Wu, Zhaofa and Xiao, Guihua and He, Jing and others},
journal={Nature Biotechnology},
pages={1--11},
year={2022},
publisher={Nature Publishing Group}
}
Z. Su, L. Xu, D. Zhong, Z. Li, F. Deng, S. Quan, L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Oct. 2022.
High-quality 4D reconstruction of human performance with complex interactions to various objects is essential in real-world scenarios, which enables numerous immersive VR/AR applications. However, recent advances still fail to provide reliable performance reconstruction, suffering from challenging interaction patterns and severe occlusions, especially for the monocular setting. To fill this gap, in this paper, we propose RobustFusion, a robust volumetric performance reconstruction system for human-object interaction scenarios using only a single RGBD sensor, which combines various data-driven visual and interaction cues to handle the complex interaction patterns and severe occlusions. We propose a semantic-aware scene decoupling scheme to model the occlusions explicitly, with a segmentation refinement and robust object tracking to prevent disentanglement uncertainty and maintain temporal consistency. We further introduce a robust performance capture scheme with the aid of various data-driven cues, which not only enables re-initialization ability, but also models the complex human-object interaction patterns in a data-driven manner. To this end, we introduce a spatial relation prior to prevent implausible intersections, as well as data-driven interaction cues to maintain natural motions, especially for those regions under severe human-object occlusions. We also adopt an adaptive fusion scheme for temporally coherent human-object reconstruction with occlusion analysis and human parsing cue. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality 4D human performance reconstruction under complex human-object interactions whilst still maintaining the lightweight monocular setting.
Latex Bibtex Citation:
@ARTICLE{9925090,
author={Su, Zhuo and Xu, Lan and Zhong, Dawei and Li, Zhong and Deng, Fan and Quan, Shuxue and Fang, Lu},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={RobustFusion: Robust Volumetric Performance Reconstruction Under Human-Object Interactions From Monocular RGBD Stream},
year={2022},
volume={},
number={},
pages={1-17},
doi={10.1109/TPAMI.2022.3215746}}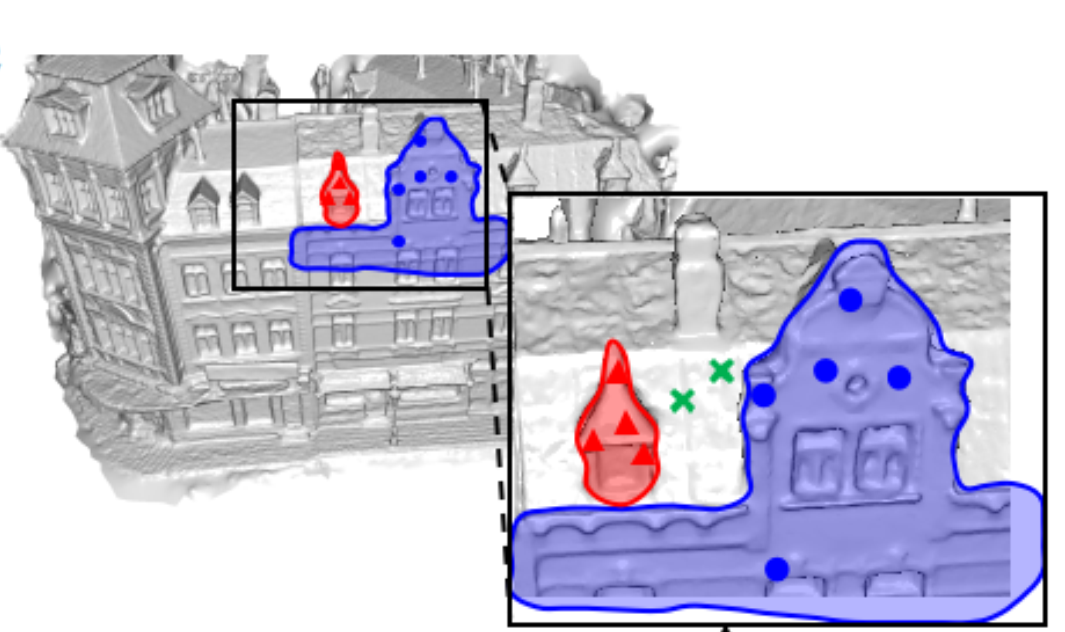
J. Zhang, R. Tang, Z. Cao, J. Xiao, R. Huang, and L. Fang,
Proc. of Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS).
Self-supervised multi-view stereopsis (MVS) attracts increasing attention for learning dense surface predictions from only a set of images without onerous ground-truth 3D training data for supervision. However, existing methods highly rely on the local photometric consistency, which fail to identify accurately dense correspondence in broad textureless or reflectant areas. In this paper, we show that geometric proximity such as surface connectedness and occlusion boundaries implicitly inferred from images could serve as reliable guidance for pixel-wise multi-view correspondences. With this insight, we present a novel elastic part representation, which encodes physically-connected part segmentations with elastically-varying scales, shapes and boundaries. Meanwhile, a self-supervised MVS framework namely ElasticMVS is proposed to learn the representation and estimate per-view depth following a part-aware propagation and evaluation scheme. Specifically, the pixel-wise part representation is trained by a contrastive learning-based strategy, which increases the representation compactness in geometrically concentrated areas and contrasts otherwise. ElasticMVS iteratively optimizes a part-level consistency loss and a surface smoothness loss, based on a set of depth hypotheses propagated from the geometrically concentrated parts. Extensive evaluations convey the superiority of ElasticMVS in the reconstruction completeness and accuracy, as well as the efficiency and scalability. Particularly, for the challenging large-scale reconstruction benchmark, ElasticMVS demonstrates significant performance gain over both the supervised and self-supervised approaches.
Latex Bibtex Citation:
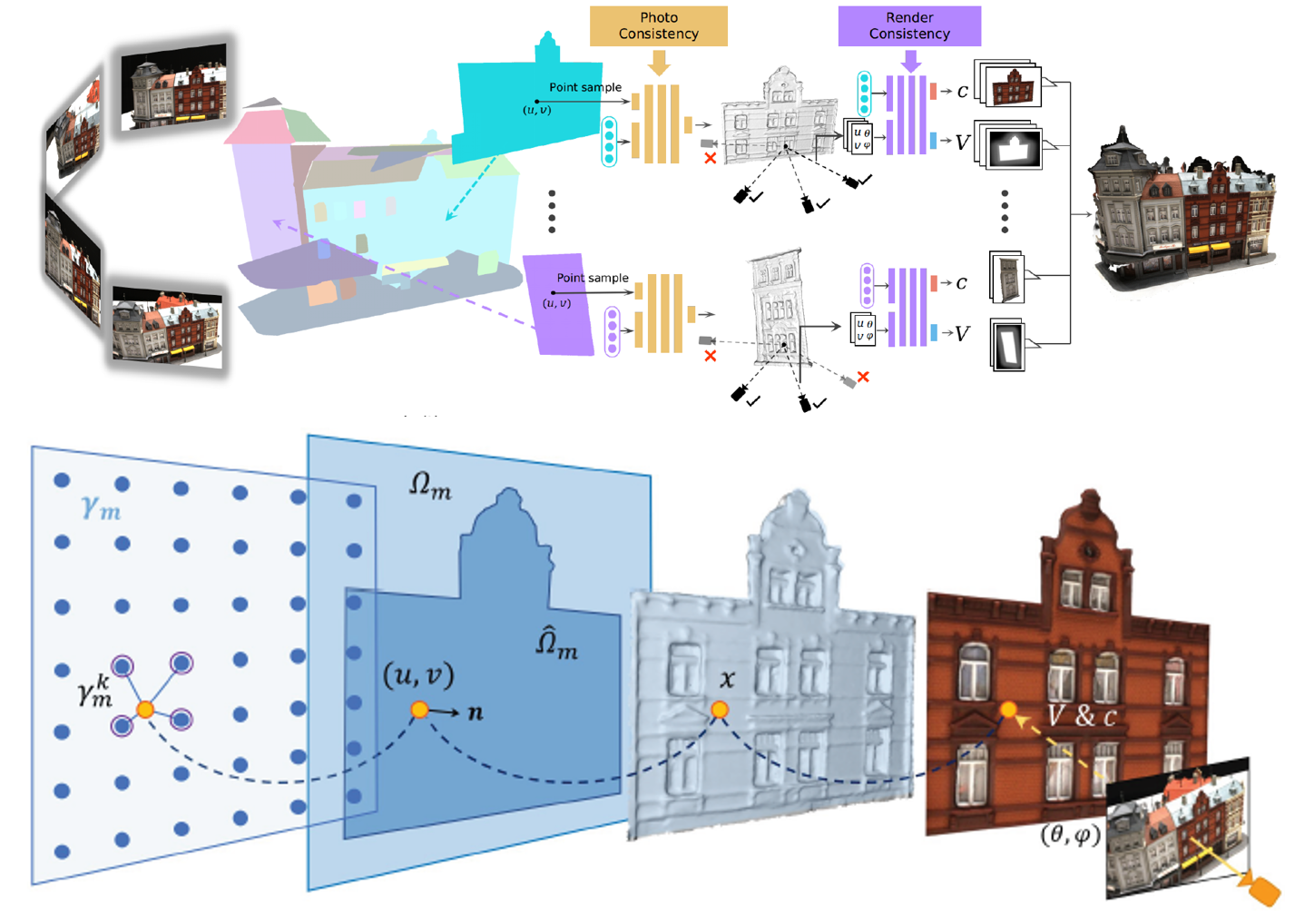
H. Ying, J. Zhang, Y. Chen, Z. Cao, J. Xiao, R. Huang, L. Fang,
Proc. of The 30th ACM International Conference on Multimedia (MM' 22).
Multi-view stereopsis (MVS) recovers 3D surfaces by finding dense photo-consistent correspondences from densely sampled images. In this paper, we tackle the challenging MVS task from sparsely sampled views (up to an order of magnitude fewer images), which is more practical and cost-efficient in applications. The major challenge comes from the significant correspondence ambiguity introduced by the severe occlusions and the highly skewed patches. On the other hand, such ambiguity can be resolved by incorporating geometric cues from the global structure. In light of this, we propose ParseMVS, boosting sparse MVS by learning the Primitive-AwaRe Surface rEpresentation. In particular, on top of being aware of global structure, our novel representation further allows for the preservation of fine details including geometry, texture, and visibility. More specifically, the whole scene is parsed into multiple geometric primitives. On each of them, the geometry is defined as the displacement along the primitives’ normal directions, together with the texture and visibility along each view direction. An unsupervised neural network is trained to learn these factors by progressively increasing the photo-consistency and render-consistency among all input images. Since the surface properties are changed locally in the 2D space of each primitive, ParseMVS can preserve global primitive structures while optimizing local details, handling the ‘incompleteness’ and the ‘inaccuracy’ problems. We experimentally demonstrate that ParseMVS constantly outperforms the state-ofthe-art surface reconstruction method in both completeness and the overall score under varying sampling sparsity, especially under the extreme sparse-MVS settings. Beyond that, ParseMVS also shows great potential in compression, robustness, and efficiency.
Latex Bibtex Citation:

S. Mao, M. Ji, B. Wang, Q. Dai, L. Fang,
IEEE Journal of Selected Topics in Signal Processing, 2022.
Accurately perceiving object surface material is critical for scene understanding and robotic manipulation. However, it is ill-posed because the imaging process entangles material, lighting, and geometry in a complex way. Appearance-based methods cannot disentangle lighting and geometry variance and have difficulties in textureless regions. We propose a novel multimodal fusion method for surface material perception using the depth camera shooting structured laser dots. The captured active infrared image was decomposed into diffusive and dot modalities and their connection with different material optical properties (i.e. reflection and scattering) were revealed separately. The geometry modality, which helps to disentangle material properties from geometry variations, is derived from the rendering equation and calculated based on the depth image obtained from the structured light camera. Further, together with the texture feature learned from the gray modality, a multimodal learning method is proposed for material perception. Experiments on synthesized and captured datasets validate the orthogonality of learned features. The final fusion method achieves 92.5% material accuracy, superior to state-of-the-art appearancebased methods (78.4%).
Latex Bibtex Citation:
@article{mao2022surface,
title={Surface Material Perception Through Multimodal Learning},
author={Mao, Shi and Ji, Mengqi and Wang, Bin and Dai, Qionghai and Fang, Lu},
journal={IEEE Journal of Selected Topics in Signal Processing},
year={2022},
publisher={IEEE}
}
We propose INS-Conv, an INcremental Sparse Convolutional network which enables online accurate 3D semantic and instance segmentation. Benefiting from the incremental nature of RGB-D reconstruction, we only need to update the residuals between the reconstructed scenes of consecutive frames, which are usually sparse. For layer design, we define novel residual propagation rules for sparse convolution operations, achieving close approximation to standard sparse convolution. For network architecture, an uncertainty term is proposed to adaptively select which residual to update, further improving the inference accuracy and efficiency. Based on INS-Conv, an online joint 3D semantic and instance segmentation pipeline is proposed, reaching an inference speed of 15 FPS on GPU and 10 FPS on CPU. Experiments on ScanNetv2 and SceneNN datasets show that the accuracy of our method surpasses previous online methods by a large margin, and is on par with state-of-the-art offline methods. A live demo on portable devices further shows the superior performance of INS-Conv.
Latex Bibtex Citation:
@inproceedings{liu2022ins,
title={INS-Conv: Incremental Sparse Convolution for Online 3D Segmentation},
author={Liu, Leyao and Zheng, Tian and Lin, Yun-Jou and Ni, Kai and Fang, Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18975--18984},
year={2022}
}
L. Han, D. Zhong, L. Li, K. Zheng and L. Fang,
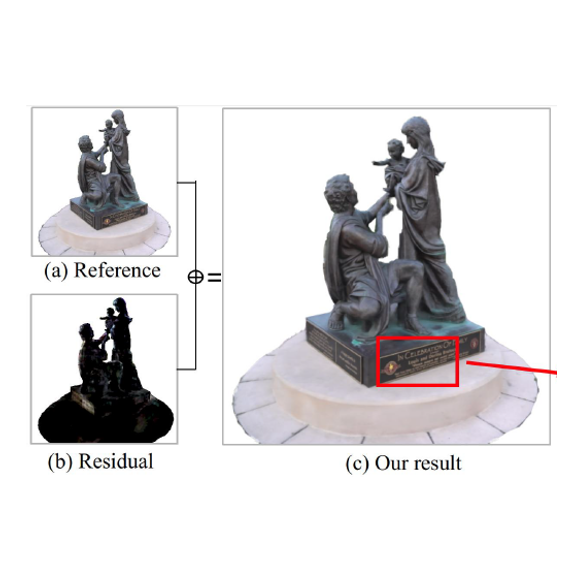
IEEE Trans. on Image Processing (TIP), Feb. 2022.
Scene Representation Networks (SRN) have been proven as a powerful tool for novel view synthesis in recent works. They learn a mapping function from the world coordinates of spatial
points to radiance color and the scene’s density using a fully connected network. However, scene texture contains complex high-frequency details in practice that is hard to be memorized by
a network with limited parameters, leading to disturbing blurry effects when rendering novel views. In this paper, we propose to learn ‘residual color’ instead of ‘radiance color’ for novel view synthesis, i.e., the residuals between surface color and reference color. Here the reference color is calculated based on spatial color priors, which are extracted from input view observations. The beauty of such a strategy lies in that the residuals between radiance color and reference are close to zero for most spatial points thus are easier to learn. A novel view synthesis system that
learns the residual color using SRN is presented in this paper. Experiments on public datasets demonstrate that the proposed method achieves competitive performance in preserving highresolution details, leading to visually more pleasant results than the state of the arts.
Latex Bibtex Citation:
@article{Han2022,
author = {Han, Lei and Zhong, Dawei and Li, Lin and Zheng, Kai and and Fang, Lu},
title = {Learning Residual Color for Novel View Synthesis},
journal = {IEEE Transactions on Image Processing (TIP)},
year = {2022},
type = {Journal Article}
}
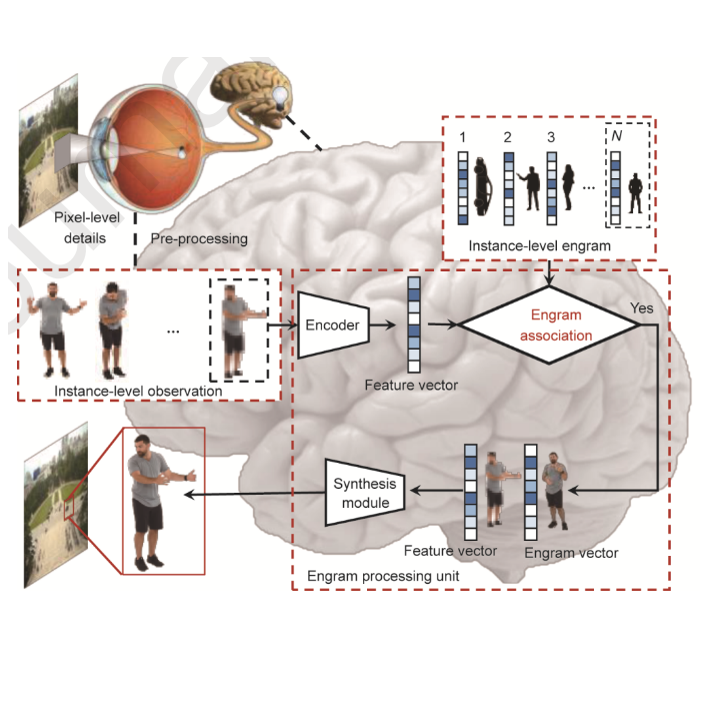
L. Fang, M. Ji, X. Yuan, J. He, J. Zhang, Y. Zhu, T. Zheng, L. Liu, B. Wang and Q. Dai
Engineering, Feb. 2022.
Sensing and understanding large-scale dynamic scenes require a high-performance imaging system. Conventional imaging systems pursue higher capability by simply increasing the pixel resolution via stitching cameras at the expense of a bulky system. Moreover, they strictly follow the feedforward pathway: that is, their pixel-level sensing is independent of semantic understanding. Differently, a human visual system owns superiority with both feedforward and feedback pathways: The feedforward pathway extracts object representation (referred to as memory engram) from visual inputs, while, in the feedback pathway, the associated engram is reactivated to generate hypotheses about an object. Inspired by this, we propose a dual-pathway imaging mechanism, called engram-driven videography. We start by abstracting the holistic representation of the scene, which is associated bidirectionally with local details, driven by an instance-level engram. Technically, the entire system works by alternating between the excitation–inhibition and association states. In the former state, pixel-level details become dynamically consolidated or inhibited to strengthen the instance-level engram. In the association state, the spatially and temporally consistent content becomes synthesized driven by its engram for outstanding videography quality of future scenes. The association state serves as the imaging of future scenes by synthesizing spatially and temporally consistent content driven by its engram. Results of extensive simulations and experiments demonstrate that the proposed system revolutionizes the conventional videography paradigm and shows great potential for videography of large-scale scenes with multi-objects.
Latex Bibtex Citation:
@article{fang2022engram,
title={Engram-Driven Videography},
author={Fang, Lu and Ji, Mengqi and Yuan, Xiaoyun and He, Jing and Zhang, Jianing and Zhu, Yinheng and Zheng, Tian and Liu, Leyao and Wang, Bin and Dai, Qionghai},
journal={Engineering},
year={2022},
publisher={Elsevier}
}
2021

T. Zhou, X. Lin, J. Wu, Y. Chen, H. Xie, Y. Li, J. Fan, H. Wu, L. Fang and Q. Dai,
Nature Photonics, 2021: 1-7. (cover article)
There is an ever-growing demand for artificial intelligence. Optical processors, which compute with photons instead of electrons, can fundamentally accelerate the development of artificial intelligence by offering substantially improved computing performance. There has been long-term interest in optically constructing the most widely used artificial-intelligence architecture, that is, artificial neural networks, to achieve brain-inspired information processing at the speed of light. However, owing to restrictions in design flexibility and the accumulation of system errors, existing processor architectures are not reconfigurable and have limited model complexity and experimental performance. Here, we propose the reconfigurable diffractive processing unit, an optoelectronic fused computing architecture based on the diffraction of light, which can support different neural networks and achieve a high model complexity with millions of neurons. Along with the developed adaptive training approach to circumvent system errors, we achieved excellent experimental accuracies for high-speed image and video recognition over benchmark datasets and a computing performance superior to that of cutting-edge electronic computing platforms.
Latex Bibtex Citation:
@article{zhou2021large,
title={Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit},
author={Zhou, Tiankuang and Lin, Xing and Wu, Jiamin and Chen, Yitong and Xie, Hao and Li, Yipeng and Fan, Jingtao and Wu, Huaqiang and Fang, Lu and Dai, Qionghai},
journal={Nature Photonics},
pages={1--7},
year={2021},
publisher={Nature Publishing Group}
}

X. Yuan, M. Ji, J. Wu, D. Brady, Q. Dai and L. Fang,
Light: Science & Applications, volume 10, Article number: 37 (2021). (cover article)
Array cameras removed the optical limitations of a single camera and paved the way for high-performance imaging via the combination of micro-cameras and computation to fuse multiple aperture images. However, existing solutions use dense arrays of cameras that require laborious calibration and lack flexibility and practicality. Inspired by the cognition function principle of the human brain, we develop an unstructured array camera system that adopts a hierarchical modular design with multiscale hybrid cameras composing different modules. Intelligent computations are designed to collaboratively operate along both intra- and intermodule pathways. This system can adaptively allocate imagery resources to dramatically reduce the hardware cost and possesses unprecedented flexibility, robustness, and versatility. Large scenes of real-world data were acquired to perform human-centric studies for the assessment of human behaviours at the individual level and crowd behaviours at the population level requiring high-resolution long-term monitoring of dynamic wide-area scenes.
Latex Bibtex Citation:
@article{yuan2021modular,
title={A modular hierarchical array camera},
author={Yuan, Xiaoyun and Ji, Mengqi and Wu, Jiamin and Brady, David J and Dai, Qionghai and Fang, Lu},
journal={Light: Science \& Applications},
volume={10},
number={1},
pages={1--9},
year={2021},
publisher={Nature Publishing Group}
}
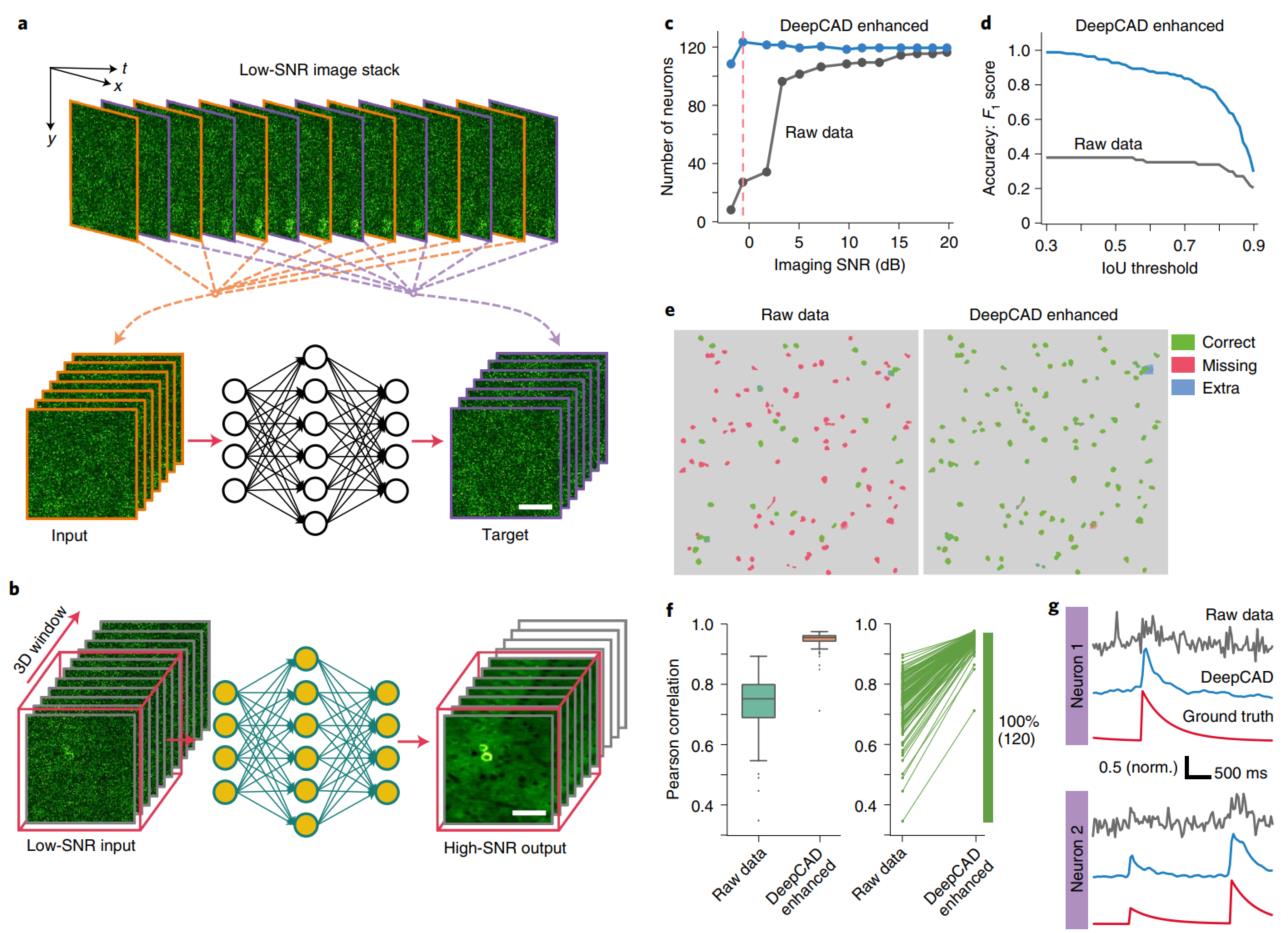
X. Li, G. Zhang, J. Wu, Y. Zhang, Z. Zhao, X. Lin, H. Qiao, H. Xie, H. Wang, L. Fang and Q. Dai,
Nature Methods, volume 18, pages 1395–1400 (2021).
Calcium imaging has transformed neuroscience research by providing a methodology for monitoring the activity of neural circuits with single-cell resolution. However, calcium imaging is inherently susceptible to detection noise, especially when imaging with high frame rate or under low excitation dosage. Here we developed DeepCAD, a self-supervised deep-learning method for spatiotemporal enhancement of calcium imaging data that does not require any high signal-to-noise ratio (SNR) observations. DeepCAD suppresses detection noise and improves the SNR more than tenfold, which reinforces the accuracy of neuron extraction and spike inference and facilitates the functional analysis of neural circuits.
Latex Bibtex Citation:
@article{li2021reinforcing,
title={Reinforcing neuron extraction and spike inference in calcium imaging using deep self-supervised denoising},
author={Li, Xinyang and Zhang, Guoxun and Wu, Jiamin and Zhang, Yuanlong and Zhao, Zhifeng and Lin, Xing and Qiao, Hui and Xie, Hao and Wang, Haoqian and Fang, Lu and others},
journal={Nature Methods},
volume={18},
number={11},
pages={1395--1400},
year={2021},
publisher={Nature Publishing Group}
}
J. Zhang, M. Ji, G. Wang, X. Zhiwei, S. Wang, L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2021.
The recent success in supervised multi-view stereopsis (MVS) relies on the onerously collected real-world 3D data. While the latest differentiable rendering techniques enable unsupervised MVS, they are restricted to discretized (e.g., point cloud) or implicit geometric representation, suffering from either low integrity for a textureless region or less geometric details for complex scenes. In this paper, we propose SurRF, an unsupervised MVS pipeline by learning Surface Radiance Field, i.e., a radiance field defined on a continuous and explicit 2D surface. Our key insight is that, in a local region, the explicit surface can be gradually deformed from a continuous initialization along view-dependent camera rays by differentiable rendering. That enables us to define the radiance field only on a 2D deformable surface rather than in a dense volume of 3D space, leading to compact representation while maintaining complete shape and realistic texture for large-scale complex scenes. We experimentally demonstrate that the proposed SurRF produces competitive results over the-state-of-the-art on various real-world challenging scenes, without any 3D supervision. Moreover, SurRF shows great potential in owning the joint advantages of mesh (scene manipulation), continuous surface (high geometric resolution), and radiance field (realistic rendering).
Latex Bibtex Citation:
@ARTICLE{9555381,
author={Zhang, Jinzhi and Ji, Mengqi and Wang, Guangyu and Zhiwei, Xue and Wang, Shengjin and Fang, Lu},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={SurRF: Unsupervised Multi-view Stereopsis by Learning Surface Radiance Field},
year={2021},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2021.3116695}}

J. Zhang, J. Zhang, S. Mao, M. Ji, G. Wang, Z. Chen, T. Zhang, X. Yuan, Q. Dai and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Sep. 2021.
Multiview stereopsis (MVS) methods, which can reconstruct both the 3D geometry and texture from multiple images, have been rapidly developed and extensively investigated from the feature engineering methods to the data-driven ones. However, there is no dataset containing both the 3D geometry of large-scale scenes and high-resolution observations of small details to benchmark the algorithms. To this end, we present GigaMVS, the first gigapixel-image-based 3D reconstruction benchmark for ultra-large-scale scenes. The gigapixel images, with both wide field-of-view and high-resolution details, can clearly observe both the Palace-scale scene structure and Relievo-scale local details. The ground-truth geometry is captured by the laser scanner, which covers ultra-large-scale scenes with an average area of 8667 m^2 and a maximum area of 32007 m^2. Due to the extremely large scale, complex occlusion, and gigapixel-level images, GigaMVS brings the problem to light that emerged from the poor effectiveness and efficiency of the existing MVS algorithms. We thoroughly investigate the state-of-the-art methods in terms of geometric and textural measurements, which point to the weakness of existing methods and promising opportunities for future works. We believe that GigaMVS can benefit the community of 3D reconstruction and support the development of novel algorithms balancing robustness, scalability, and accuracy.
Latex Bibtex Citation:
@ARTICLE{9547729,
author={Zhang, Jianing and Zhang, Jinzhi and Mao, Shi and Ji, Mengqi and Wang, Guangyu and Chen, Zequn and Zhang, Tian and Yuan, Xiaoyun and Dai, Qionghai and Fang, Lu},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={GigaMVS: A Benchmark for Ultra-large-scale Gigapixel-level 3D Reconstruction},
year={2021},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2021.3115028}}
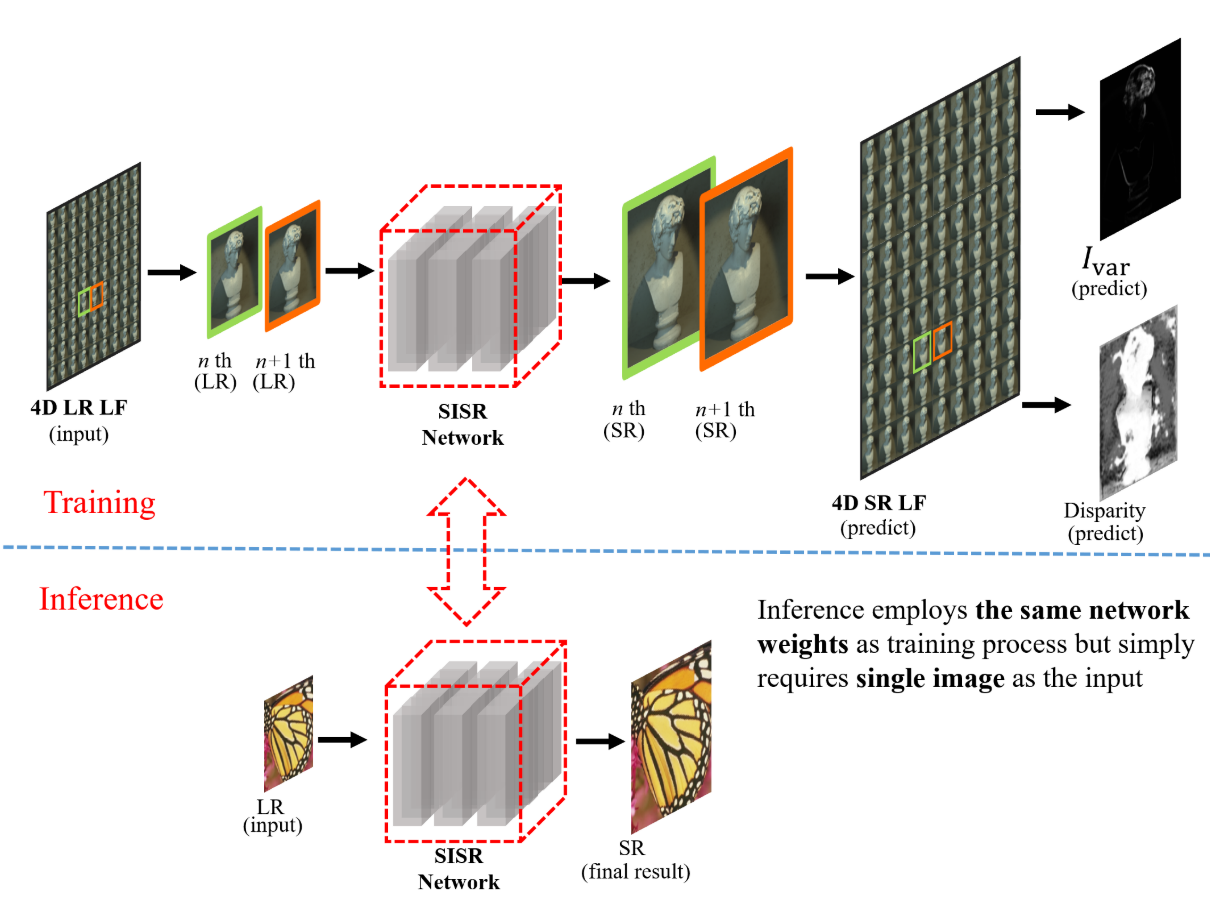
D. Jin, M. Ji, L. Xu, G. Wu, L. Wang, and L. Fang,
IEEE Trans. on Image Processing (TIP), Feb. 2021.
Learning-based single image super-resolution (SISR) aims to learn a versatile mapping from low resolution (LR) image to its high resolution (HR) version. The critical challenge is to bias the network training towards continuous and sharp edges. For the first time in this work, we propose an implicit boundary prior learnt from multi-view observations to significantly mitigate the challenge in SISR we outline. Specifically, the multi-image prior that encodes both disparity information and boundary structure of the scene supervise a SISR network for edge-preserving. For simplicity, in the training procedure of our framework, light field (LF) serves as an effective multi-image prior, and a hybrid loss function jointly considers the content, structure, variance as well as disparity information from 4D LF data. Consequently, for inference, such a general training scheme boosts the performance of various SISR networks, especially for the regions along edges. Extensive experiments on representative backbone SISR architectures constantly show the effectiveness of the proposed method, leading to around 0.6 dB gain without modifying the network architecture.
Latex Bibtex Citation:
@article{RN455,
author = {Jin, Dingjian and Ji, Mengqi and Xu, Lan and Wu, Gaochang and Wang, Liejun and Fang, Lu},
title = {Boosting Single Image Super-Resolution Learnt From Implicit Multi-Image Prior},
journal = {IEEE Transactions on Image Processing (TIP)},
volume = {30},
pages = {3240-3251},
ISSN = {1941-0042 (Electronic)
1057-7149 (Linking)},
DOI = {10.1109/TIP.2021.3059507},
url = {https://www.ncbi.nlm.nih.gov/pubmed/33621177},
year = {2021},
type = {Journal Article}
}

M. Hu, Y. Li, L. Fang and S. Wang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2021.
Learning pyramidal feature representations is crucial for recognizing object instances at different scales. Feature Pyramid Network (FPN) is the classic architecture to build a feature pyramid with high-level semantics throughout. However, intrinsic defects in feature extraction and fusion inhibit FPN from further aggregating more discriminative features. In this work, we propose Attention Aggregation based Feature Pyramid Network (A2 -FPN), to improve multi-scale feature learning through attention-guided feature aggregation. In feature extraction, it extracts discriminative features by collecting-distributing multi-level global context features, and mitigates the semantic information loss due to drastically reduced channels. In feature fusion, it aggregates complementary information from adjacent features to generate location-wise reassembly kernels for content-aware sampling, and employs channelwise reweighting to enhance the semantic consistency before element-wise addition. A2 -FPN shows consistent gains on different instance segmentation frameworks. By replacing FPN with A2 -FPN in Mask R-CNN, our model boosts the performance by 2.1% and 1.6% mask AP when using ResNet-50 and ResNet-101 as backbone, respectively. Moreover, A2 -FPN achieves an improvement of 2.0% and 1.4% mask AP when integrated into the strong baselines such as Cascade Mask R-CNN and Hybrid Task Cascade.
Latex Bibtex Citation:
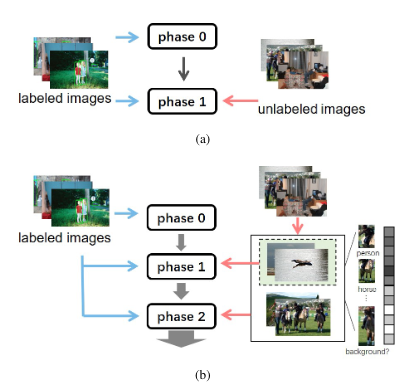
Z. Wang, Y. Li, Y. Guo, L. Fang and S. Wang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2021.
In this paper, we delve into semi-supervised object detec-tion where unlabeled images are leveraged to break throughthe upper bound of fully-supervised object detection. Pre-vious semi-supervised methods based on pseudo labels areseverely degenerated by noise and prone to overfit to noisylabels, thus are deficient in learning different unlabeledknowledge well. To address this issue, we propose a data-uncertainty guided multi-phase learning method for semi-supervised object detection. We comprehensively considerdivergent types of unlabeled images according to their dif-ficulty levels, utilize them in different phases, and ensemblemodels from different phases together to generate ultimateresults. Image uncertainty guided easy data selection andregion uncertainty guided RoI Re-weighting are involved inmulti-phase learning and enable the detector to concentrateon more certain knowledge. Through extensive experimentson PASCAL VOC and MS COCO, we demonstrate that ourmethod behaves extraordinarily compared to baseline ap-proaches and outperforms them by a large margin, morethan3%on VOC and2%on COCO.
Latex Bibtex Citation:
@article{wang2021data,
title={Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection},
author={Wang, Zhenyu and Li, Yali and Guo, Ye and Fang, Lu and Wang, Shengjin},
journal={arXiv preprint arXiv:2103.16368},
year={2021}
}
2020
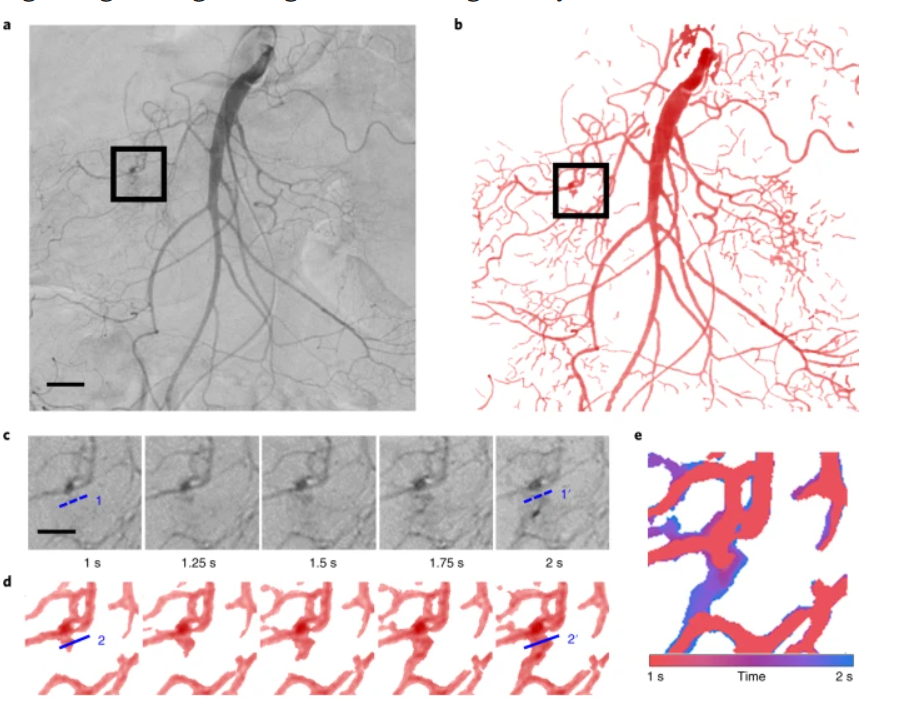
Vascular disease is one of the leading causes of death and threatens human health worldwide. Imaging examination of vascular pathology with reduced invasiveness is challenging due to the intrinsic vasculature complexity and non-uniform scattering from bio-tissues. Here, we report VasNet, a vasculature-aware unsupervised learning algorithm that augments pathovascular recognition from small sets of unlabelled fluorescence and digital subtraction angiography images. VasNet adopts a multi-scale fusion strategy with a domain adversarial neural network loss function that induces biased pattern reconstruction by strengthening features relevant to the retinal vasculature reference while weakening irrelevant features. VasNet delivers the outputs ‘Structure + X’ (where X refers to multi-dimensional features such as blood flows, the distinguishment of blood dilation and its suspicious counterparts, and the dependence of new pattern emergence on disease progression). Therefore, explainable imaging output from VasNet and other algorithm extensions holds the promise to augment medical diagnosis, as it improves performance while reducing the cost of human expertise, equipment and time consumption.
Latex Bibtex Citation:
@article{wang2020augmenting,
title={Augmenting vascular disease diagnosis by vasculature-aware unsupervised learning},
author={Wang, Yong and Ji, Mengqi and Jiang, Shengwei and Wang, Xukang and Wu, Jiamin and Duan, Feng and Fan, Jingtao and Huang, Laiqiang and Ma, Shaohua and Fang, Lu and others},
journal={Nature Machine Intelligence},
volume={2},
number={6},
pages={337--346},
year={2020},
publisher={Nature Publishing Group}
}

T. Zheng, G. Zhang, L. Han, L. Xu and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
Scalable geometry reconstruction and understanding is an important yet unsolved task. Current methods often suffer from false loop closures when there are similar-looking rooms in the scene, and often lack online scene understanding. We propose BuildingFusion, a semantic-aware structural building-scale reconstruction system, which not only allows building-scale dense reconstruction collaboratively, but also provides semantic and structural information on-the-fly. Technically, the robustness to similar places is enabled by a novel semantic-aware room-level loop closure detection(LCD) method. The insight lies in that even though local views may look similar in different rooms, the objects inside and their locations are usually different, implying that the semantic information forms a unique and compact representation for place recognition. To achieve that, a 3D convolutional network is used to learn instance-level embeddings for similarity measurement and candidate selection, followed by a graph matching module for geometry verification. On the system side, we adopt a centralized architecture to enable collaborative scanning. Each agent reconstructs a part of the scene, and the combination is activated when the overlaps are found using room-level LCD, which is performed on the server. Extensive comparisons demonstrate the superiority of the semantic-aware room-level LCD over traditional image-based LCD. Live demo on the real-world building-scale scenes shows the feasibility of our method with robust, collaborative, and real-time performance.
Latex Bibtex Citation:
@ARTICLE{9286413,
author={T. {Zheng} and G. {Zhang} and L. {Han} and L. {Xu} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Building Fusion: Semantic-aware Structural Building-scale 3D Reconstruction},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.3042881}}

L. Han, S. Gu, D. Zhong, S. Quan and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
High-quality reconstruction of 3D geometry and texture plays a vital role in providing immersive perception of the real world. Additionally, online computation enables the practical usage of 3D reconstruction for interaction. We present an RGBD-based globally-consistent dense 3D reconstruction approach, accompanying high-resolution (< 1 cm) geometric reconstruction and high-quality (the spatial resolution of the RGB image) texture mapping, both of which work online using the CPU computing of a portable device merely. For geometric reconstruction, we introduce a sparse voxel sampling scheme employing the continuous nature of surfaces in 3D space, reducing more than 95% of the computational burden compared with conventional volumetric fusion approaches. For online texture mapping, we propose a simplified incremental MRF solver, which utilizes previous optimization results for faster convergence, and an efficient reference-based color adjustment scheme for texture optimization. Quantitative and qualitative experiments demonstrate that our online scheme achieves a more realistic visualization of the environment with more abundant details, while taking more compact memory consumption and much lower computational complexity than existing solutions.
Latex Bibtex Citation:
@ARTICLE{9184935,
author={L. {Han} and S. {Gu} and D. {Zhong} and s. {quan} and L. {FANG}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Real-time Globally Consistent Dense 3D Reconstruction with Online Texturing},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.3021023}}

M. Ji, J. Zhang, Q. Dai and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since sparser sampling is always more favorable inpractice. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for thecase with larger baseline angle that worsens the photo-consistency check. As another line of solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and 'inaccuracy' problems induced by very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and the state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting.
Latex Bibtex Citation:
@ARTICLE{ji2020surfacenet_plus,
title={SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis},
author={M. {Ji} and J. {Zhang} and Q. {Dai} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2020},
volume={},
number={},
pages={1-1},
}

Y. Tang, H. Zheng, Y. Zhu, X. Yuan, X. Lin, D. Brady and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
The ability of camera arrays to efficiently capture higher space-bandwidth product than single cameras has led to various multiscale and hybrid systems. These systems play vital roles in computational photography, including light field imaging, 360 VR camera, gigapixel videography, etc. One of the critical tasks in multiscale hybrid imaging is matching and fusing cross-resolution images from different cameras under perspective parallax. In this paper, we investigate the reference-based super-resolution (RefSR) problem associated with dual-camera or multi-camera systems, with a significant resolution gap (8x) and large parallax (10%pixel displacement). We present CrossNet++, an end-to-end network containing novel two-stage cross-scale warping modules. The stage I learns to narrow down the parallax distinctively with the strong guidance of landmarks and intensity distribution consensus. Then the stage II operates more fine-grained alignment and aggregation in feature domain to synthesize the final super-resolved image. To further address the large parallax, new hybrid loss functions comprising warping loss, landmark loss and super-resolution loss are proposed to regularize training and enable better convergence. CrossNet++ significantly outperforms the state-of-art on light field datasets as well as real dual-camera data. We further demonstrate the generalization of our framework by transferring it to video super-resolution and video denoising.
Latex Bibtex Citation:
@ARTICLE{9099445,
author={Y. {Tan} and H. {Zheng} and Y. {Zhu} and X. {Yuan} and X. {Lin} and D. {Brady} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={CrossNet++: Cross-scale Large-parallax Warping for Reference-based Super-resolution},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.2997007}}
L. Han, T. Zheng, Y. Zhu, L. Xu and L. Fang,
IEEE VR & IEEE Trans. on Visualization and Computer Graphics (TVCG), 2020. (Oral)
Semantic understanding of 3D environments is critical for both the unmanned system and the human involved virtual/augmented reality (VR/AR) immersive experience. Spatially-sparse convolution, taking advantage of the intrinsic sparsity of 3D point cloud data, makes high resolution 3D convolutional neural networks tractable with state-of-the-art results on 3D semantic segmentation problems. However, the exhaustive computations limits the practical usage of semantic 3D perception for VR/AR applications in portable devices. In this paper, we identify that the efficiency bottleneck lies in the unorganized memory access of the sparse convolution steps, i.e., the points are stored independently based on a predefined dictionary, which is inefficient due to the limited memory bandwidth of parallel computing devices (GPU). With the insight that points are continuous as 2D surfaces in 3D space, a chunk-based sparse convolution scheme is proposed to reuse the neighboring points within each spatially organized chunk. An efficient multi-layer adaptive fusion module is further proposed for employing the spatial consistency cue of 3D data to further reduce the computational burden. Quantitative experiments on public datasets demonstrate that our approach works 11× faster than previous approaches with competitive accuracy. By implementing both semantic and geometric 3D reconstruction simultaneously on a portable tablet device, we demo a foundation platform for immersive AR applications.
Latex Bibtex Citation:
@ARTICLE{8998140,
author={L. {Han} and T. {Zheng} and Y. {Zhu} and L. {Xu} and L. {Fang}},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Live Semantic 3D Perception for Immersive Augmented Reality},
year={2020},
volume={26},
number={5},
pages={2012-2022},
doi={10.1109/TVCG.2020.2973477}}

D. Brady, L. Fang and Z. Ma,
Advances in Optics and Photonics, 2020.
We review the impact of deep-learning technologies on camera architecture. The function of a camera is first to capture visual information and second to form an image. Conventionally, both functions are implemented in physical optics. Throughout the digital age, however, joint design of physical sampling and electronic processing, e.g., computational imaging, has been increasingly applied to improve these functions. Over the past five years, deep learning has radically improved the capacity of computational imaging. Here we briefly review the development of artificial neural networks and their recent intersection with computational imaging. We then consider in more detail how deep learning impacts the primary strategies of computational photography: focal plane modulation, lens design, and robotic control. With focal plane modulation, we show that deep learning improves signal inference to enable faster hyperspectral, polarization, and video capture while reducing the power per pixel by 10{\textminus}100{\texttimes}. With lens design, deep learning improves multiple aperture image fusion to enable task-specific array cameras. With control, deep learning enables dynamic scene-specific control that may ultimately enable cameras that capture the entire optical data cube (the ``light field''), rather than just a focal slice. Finally, we discuss how these three strategies impact the physical camera design as we seek to balance physical compactness and simplicity, information capacity, computational complexity, and visual fidelity.
Latex Bibtex Citation:
@article{Brady:20,
author = {David J. Brady and Lu Fang and Zhan Ma},
journal = {Adv. Opt. Photon.},
keywords = {Extended depth of field; Image processing; Image quality; Imaging systems; Optical imaging; Signal processing},
number = {4},
pages = {787--846},
publisher = {OSA},
title = {Deep learning for camera data acquisition, control, and image estimation},
volume = {12},
month = {Dec},
year = {2020},
url = {http://aop.osa.org/abstract.cfm?URI=aop-12-4-787},
doi = {10.1364/AOP.398263},
T. Zhou, L. Fang, T. Yan, J. Wu, Y. Li, J. Fan, H. Wu, X. Lin, and Q. Dai,
Photonics Research, Vol. 8, No. 6, pp.940-953, 2020.
Training an artificial neural network with backpropagation algorithms to perform advanced machine learning tasks requires an extensive computational process. This paper proposes to implement the backpropagation algorithm optically for in situ training of both linear and nonlinear diffractive optical neural networks, which enables the acceleration of training speed and improvement in energy efficiency on core computing modules. We demonstrate that the gradient of a loss function with respect to the weights of diffractive layers can be accurately calculated by measuring the forward and backward propagated optical fields based on light reciprocity and phase conjunction principles. The diffractive modulation weights are updated by programming a high-speed spatial light modulator to minimize the error between prediction and target output and perform inference tasks at the speed of light. We numerically validate the effectiveness of our approach on simulated networks for various applications. The proposed in situ optical learning architecture achieves accuracy comparable to in silico training with an electronic computer on the tasks of object classification and matrix-vector multiplication, which further allows the diffractive optical neural network to adapt to system imperfections. Also, the self-adaptive property of our approach facilitates the novel application of the network for all-optical imaging through scattering media. The proposed approach paves the way for robust implementation of large-scale diffractive neural networks to perform distinctive tasks all-optically.
Latex Bibtex Citation:
@article{Zhou:20,
author = {Tiankuang Zhou and Lu Fang and Tao Yan and Jiamin Wu and Yipeng Li and Jingtao Fan and Huaqiang Wu and Xing Lin and Qionghai Dai},
journal = {Photon. Res.},
keywords = {Diffractive optical elements; Light fields; Optical fields; Optical networks; Optical neural systems; Phase shifting digital holography},
number = {6},
pages = {940--953},
publisher = {OSA},
title = {In situ optical backpropagation training of diffractive optical neural networks},
volume = {8},
month = {Jun},
year = {2020},
url = {http://www.osapublishing.org/prj/abstract.cfm?URI=prj-8-6-940},
doi = {10.1364/PRJ.389553}
}

D. Jin, A. Zhang, J. Wu, G. Wu, and L. Fang,
Proc. of The 28th ACM International Conference on Multimedia (MM '20)
Light-field (LF) camera holds great promise for passive/general depth estimation benefited from high angular resolution, yet suffering small baseline for distanced region. While stereo solution with large baseline is superior to handle distant scenarios, the problem of limited angular resolution becomes bothering for near objects. Aiming for all-in-depth solution, we propose a cross-baseline LF camera using a commercial LF camera and a monocular camera, which naturally form a 'stereo camera' enabling compensated baseline for LF camera. The idea is simple yet non-trivial, due to the significant angular resolution gap and baseline gap between LF and stereo cameras. Fusing two depth maps from LF and stereo modules in spatial domain is fluky, which relies on the imprecisely predicted depth to distinguish close or distance range, and determine the weights for fusion. Alternatively, taking the unified representation for both LF and monocular sub-aperture view in epipolar plane image (EPI) domain, we show that for each pixel, the minimum variance along different shearing degrees in EPI domain estimates its depth with the highest fidelity. By minimizing the minimum variance, the depth error is minimized accordingly. The insight is that the calculated minimum variance in EPI domain owns higher fidelity than the predicted depth in spatial domain. Extensive experiments demonstrate the superiority of our cross-baseline LF camera in providing high-quality all-in-depth map from 0.2m to 100m.
Latex Bibtex Citation:
@article{Jin2020AllindepthVC,
title={All-in-depth via Cross-baseline Light Field Camera},
author={Dingjian Jin and A. Zhang and Jiamin Wu and Gaochang Wu and Haoqian Wang and Lu Fang},
journal={Proceedings of the 28th ACM International Conference on Multimedia},
year={2020}
}
L. Xu, W. Xu, V. Golyanik, M. Habermann, L. Fang and C. Theobalt,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2020. (Oral)
The high frame rate is a critical requirement for capturing fast human motions. In this setting, existing markerless image-based methods are constrained by the lighting requirement, the high data bandwidth and the consequent high computation overhead. In this paper, we propose EventCap - the first approach for 3D capturing of high-speed human motions using a single event camera. Our method combines model-based optimization and CNN-based human pose detection to capture high frequency motion details and to reduce the drifting in the tracking. As a result, we can capture fast motions at millisecond resolution with significantly higher data efficiency than using high frame rate videos. Experiments on our new event-based fast human motion dataset demonstrate the effectiveness and accuracy of our method, as well as its robustness to challenging lighting conditions.
Latex Bibtex Citation:
@INPROCEEDINGS{9157340,
author={L. {Xu} and W. {Xu} and V. {Golyanik} and M. {Habermann} and L. {Fang} and C. {Theobalt}},
booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={EventCap: Monocular 3D Capture of High-Speed Human Motions Using an Event Camera},
year={2020},
volume={},
number={},
pages={4967-4977},
doi={10.1109/CVPR42600.2020.00502}}

X. Wang, X. Zhang, Y. Zhu, Y. Guo, X. Yuan, G. Ding, Q. Dai, D. Brady and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2020.
We present PANDA, the first gigaPixel-level humAN-centric viDeo dAtaset, for large-scale, long-term, and multi-object visual analysis. The videos in PANDA were captured by a gigapixel camera and cover real-world scenes with both wide field-of-view (~1 square kilometer area) and high-resolution details (~gigapixel-level/frame). The scenes may contain 4k head counts with over 100× scale variation. PANDA provides enriched and hierarchical ground-truth annotations, including 15,974.6k bounding boxes, 111.8k fine-grained attribute labels, 12.7k trajectories, 2.2k groups and 2.9k interactions. We benchmark the human detection and tracking tasks. Due to the vast variance of pedestrian pose, scale, occlusion and trajectory, existing approaches are challenged by both accuracy and efficiency. Given the uniqueness of PANDA with both wide FoV and high resolution, a new task of interaction-aware group detection is introduced. We design a `global-to-local zoom-in' framework, where global trajectories and local interactions are simultaneously encoded, yielding promising results. We believe PANDA will contribute to the community of artificial intelligence and praxeology by understanding human behaviors and interactions in large-scale real-world scenes. PANDA Website: http://www.panda-dataset.com.
Latex Bibtex Citation:
@INPROCEEDINGS{9156646,
author={X. {Wang} and X. {Zhang} and Y. {Zhu} and Y. {Guo} and X. {Yuan} and L. {Xiang} and Z. {Wang} and G. {Ding} and D. {Brady} and Q. {Dai} and L. {Fang}},
booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={PANDA: A Gigapixel-Level Human-Centric Video Dataset},
year={2020},
volume={},
number={},
pages={3265-3275},
doi={10.1109/CVPR42600.2020.00333}}
}
L. Han, T. Zheng, L. Xu and L. Fang,
Proc. of Computer Vision and Pattern Recognition (CVPR), 2020.
3D instance segmentation, with a variety of applications in robotics and augmented reality, is in large demands these days. Unlike 2D images that are projective observations of the environment, 3D models provide metric reconstruction of the scenes without occlusion or scale ambiguity. In this paper, we define “3D occupancy size”, as the number of voxels occupied by each instance. It owns advantages of robustness in prediction, on which basis, OccuSeg, an occupancy-aware 3D instance segmentation scheme is proposed. Our multi-task learning produces both occupancy signal and embedding representations, where the training of spatial and feature embeddings varies with their difference in scale-aware. Our clustering scheme benefits from the reliable comparison between the predicted occupancy size and the clustered occupancy size, which encourages hard samples being correctly clustered and avoids over segmentation. The proposed approach achieves state-of-theart performance on 3 real-world datasets, i.e. ScanNetV2, S3DIS and SceneNN, while maintaining high efficiency.
Latex Bibtex Citation:
@INPROCEEDINGS{9157103,
author={L. {Han} and T. {Zheng} and L. {Xu} and L. {Fang}},
booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={OccuSeg: Occupancy-Aware 3D Instance Segmentation},
year={2020},
volume={},
number={},
pages={2937-2946},
doi={10.1109/CVPR42600.2020.00301}}

J. Zhang, T. Zhu, A. Zhang, Z. Wang, X. Yuan, Q. Dai and L. Fang,
Proc. of Int. Conf. on Computational Photography (ICCP),2020. (Oral)
Creating virtual reality (VR) content with effective imaging systems has attracted significant attention worldwide following the broad applications of VR in various fields, including entertainment, surveillance, sports, etc. However, due to the inherent trade-off between field-of-view and resolution of the imaging system as well as the prohibitive computational cost, live capturing and generating multiscale 360° 3D video content at an eye-limited resolution to provide immersive VR experiences confront significant challenges. In this work, we propose Multiscale-VR, a multiscale unstructured camera array computational imaging system for high-quality gigapixel 3D panoramic videography that creates the six-degree-of-freedom multiscale interactive VR content. The Multiscale-VR imaging system comprises scalable cylindrical-distributed global and local cameras, where global stereo cameras are stitched to cover 360° field-of-view, and unstructured local monocular cameras are adapted to the global camera for flexible high-resolution video streaming arrangement. We demonstrate that a high-quality gigapixel depth video can be faithfully reconstructed by our deep neural network-based algorithm pipeline where the global depth via stereo matching and the local depth via high-resolution RGB-guided refinement are associated. To generate the immersive 3D VR content, we present a three-layer rendering framework that includes an original layer for scene rendering, a diffusion layer for handling occlusion regions, and a dynamic layer for efficient dynamic foreground rendering. Our multiscale reconstruction architecture enables the proposed prototype system for rendering highly effective 3D, 360° gigapixel live VR video at 30 fps from the captured high-throughput multiscale video sequences. The proposed multiscale interactive VR content generation approach by using a heterogeneous camera system design, in contrast to the existing single-scale VR imaging systems with structured homogeneous cameras, will open up new avenues of research in VR and provide an unprecedented immersive experience benefiting various novel applications.
Latex Bibtex Citation:
@INPROCEEDINGS{9105244,
author={J. {Zhang} and T. {Zhu} and A. {Zhang} and X. {Yuan} and Z. {Wang} and S. {Beetschen} and L. {Xu} and X. {Lin} and Q. {Dai} and L. {Fang}},
booktitle={2020 IEEE International Conference on Computational Photography (ICCP)},
title={Multiscale-VR: Multiscale Gigapixel 3D Panoramic Videography for Virtual Reality},
year={2020},
volume={},
number={},
pages={1-12},
doi={10.1109/ICCP48838.2020.9105244}}
2019

L. Xu, Z. Su, L. Han, T. Yu, Y. Liu and L. Fang,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), special issue on RGB-D Vision, April 2019.
A high-quality 4D geometry and texture reconstruction for human activities usually requires multiview perceptions via highly structured multi-camera setup, where both the specifically designed cameras and the tedious pre-calibration restrict the popularity of professional multi-camera systems for daily applications. In this paper, we propose UnstructuredFusion, a practicable realtime markerless human performance capture method using unstructured commercial RGBD cameras. Along with the flexible hardware setup using simply three unstructured RGBD cameras without any careful pre-calibration, the challenge 4D reconstruction through multiple asynchronous videos is solved by proposing three novel technique contributions, i.e., online multi-camera calibration, skeleton warping based non-rigid tracking, and temporal blending based atlas texturing. The overall insights behind lie in the solid global constraints of human body and human motion which are modeled by the skeleton and the skeleton warping, respectively. Extensive experiments such as allocating three cameras flexibly in a handheld way demonstrate that the proposed UnstructuredFusion achieves high-quality 4D geometry and texture reconstruction without tiresome pre-calibration, liberating the cumbersome hardware and software restrictions in conventional structured multi-camera system, while eliminating the inherent occlusion issues of the single camera setup.
Latex Bibtex Citation:
@ARTICLE{8708933,
author={L. {Xu} and Z. {Su} and L. {Han} and T. {Yu} and Y. {Liu} and L. {Fang}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={UnstructuredFusion: Realtime 4D Geometry and Texture Reconstruction Using Commercial RGBD Cameras},
year={2020},
volume={42},
number={10},
pages={2508-2522},
doi={10.1109/TPAMI.2019.2915229}}
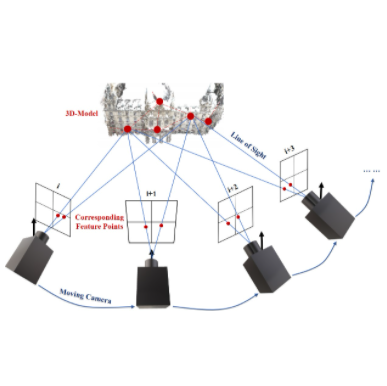
L. Han, L. Xu, D. Bobkov, E. Steinbach and L. Fang,
IEEE Trans. on Robotics (TRO) , July 2018.
Real-time globally consistent camera localization is critical for visual simultaneous localization and mapping (SLAM) applications. Regardless the popularity of high efficient pose graph optimization as a backend in SLAM, its deficiency in accuracy can hardly benefit the reconstruction application. An alternative solution for the sake of high accuracy would be global registration, which minimizes the alignment error of all the corresponding observations, yet suffers from high complexity due to the tremendous observations that need to be considered. In this paper, we start by analyzing the complexity bottleneck of global point cloud registration problem, i.e., each observation (three-dimensional point feature) has to be linearized based on its local coordinate (camera poses), which however is nonlinear and dynamically changing, resulting in extensive computation during optimization. We further prove that such nonlinearity can be decoupled into linear component (feature position) and nonlinear components (camera poses), where the former linear one can be effectively represented by its compact second-order statistics, while the latter nonlinear one merely requires six degrees of freedom for each camera pose. Benefiting from the decoupled representation, the complexity can be significantly reduced without sacrifice in accuracy. Experiments show that the proposed algorithm achieves globally consistent pose estimation in real-time via CPU computing, and owns comparable accuracy as state-of-the-art that use GPU computing, enabling the practical usage of globally consistent RGB-D SLAM on highly computationally constrained devices.
Latex Bibtex Citation:
@ARTICLE{8606275, author={L. {Han} and L. {Xu} and D. {Bobkov} and E. {Steinbach} and L. {Fang}}, journal={IEEE Transactions on Robotics}, title={Real-Time Global Registration for Globally Consistent RGB-D SLAM}, year={2019}, volume={35}, number={2}, pages={498-508}, doi={10.1109/TRO.2018.2882730}}
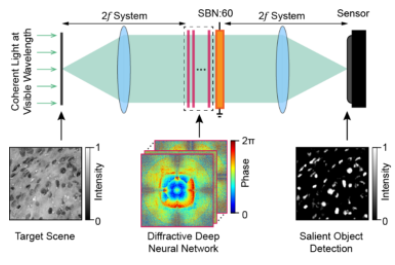
T. Yan, J. Wu, T. Zhou, H. Xie, J. Fan, L. Fang, X. Lin and Q. Dai,
Physical Review Letters (PRL), July 2019.
In this Letter we propose the Fourier-space diffractive deep neural network (F−D2NN) for all-optical image processing that performs advanced computer vision tasks at the speed of light. The F−D2NN is achieved by placing the extremely compact diffractive modulation layers at the Fourier plane or both Fourier and imaging planes of an optical system, where the optical nonlinearity is introduced from ferroelectric thin films. We demonstrated that F−D2NN can be trained with deep learning algorithms for all-optical saliency detection and high-accuracy object classification.
Latex Bibtex Citation:
@article{article,
author = {Yan, Tao and Wu, Jiamin and Tiankuang, Zhou and Xie, Hao and Xu, Feng and Fan, Jingtao and Fang, Lu and Lin, Xing and Dai, Qionghai},
year = {2019},
month = {07},
pages = {},
title = {Fourier-space Diffractive Deep Neural Network},
volume = {123},
journal = {Physical Review Letters},
doi = {10.1103/PhysRevLett.123.023901}
}

D. Zhong, L. Han and L. Fang,
Proc. of The 27th ACM International Conference on Multimedia (MM '19).
We present a practical fast, globally consistent and robust dense 3D reconstruction system, iDFusion, by exploring the joint benefit of both the visual (RGB-D) solution and inertial measurement unit (IMU). A global optimization considering all the previous states is adopted to maintain high localization accuracy and global consistency, yet its complexity of being linear to the number of all previous camera/IMU observations seriously impedes real-time implementation. We show that the global optimization can be solved efficiently at the complexity linear to the number of keyframes, and further realize a real-time dense 3D reconstruction system given the estimated camera states. Meanwhile, for the sake of robustness, we propose a novel loop-validity detector based on the estimated bias of the IMU state. By checking the consistency of camera movements, a false loop closure constraint introduces manifest inconsistency between the camera movements and IMU measurements. Experiments reveal that iDFusion owns superior reconstruction performance running in 25 fps on CPU computing of portable devices, under challenging yet practical scenarios including texture-less, motion blur, and repetitive contents.
Latex Bibtex Citation:
@inproceedings{10.1145/3343031.3351085, author = {Zhong, Dawei and Han, Lei and Fang, Lu}, title = {IDFusion: Globally Consistent Dense 3D Reconstruction from RGB-D and Inertial Measurements}, year = {2019}, isbn = {9781450368896}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3343031.3351085}, doi = {10.1145/3343031.3351085}, booktitle = {Proceedings of the 27th ACM International Conference on Multimedia}, pages = {962–970}, numpages = {9}, keywords = {loop closure, visual-imu global optimization, 3d reconstruction, real-time slam}, location = {Nice, France}, series = {MM '19} }
Y. Zhang, T. Zhou, X. Hu, X. Li, L. Fang, L. Kong, and Q. Dai,
Optics Express, vol. 27, pp. 20117-20132, July 2019.
Compared to point-scanning multiphoton microscopy, line-scanning temporal focusing microscopy (LTFM) is competitive in high imaging speed while maintaining tight axial confinement. However, considering its wide-field detection mode, LTFM suffers from shallow penetration depth as a result of the crosstalk induced by tissue scattering. In contrast to the spatial filtering based on confocal slit detection, here we propose the extended detection LTFM (ED-LTFM), the first wide-field two-photon imaging technique to extract signals from scattered photons and thus effectively extend the imaging depth. By recording a succession of line-shape excited signals in 2D and reconstructing signals under Hessian regularization, we can push the depth limitation of wide-field imaging in scattering tissues. We validate the concept with numerical simulations, and demonstrate the performance of enhanced imaging depth in in vivo imaging of mouse brains.
Latex Bibtex Citation:
@article{Zhang:19,
author = {Yuanlong Zhang and Tiankuang Zhou and Xuemei Hu and Xinyang Li and Hao Xie and Lu Fang and Lingjie Kong and Qionghai Dai},
journal = {Opt. Express},
keywords = {High speed imaging; In vivo imaging; Laser materials processing; Multiphoton microscopy; Spatial filtering; Two photon imaging},
number = {15},
pages = {20117--20132},
publisher = {OSA},
title = {Overcoming tissue scattering in wide-field two-photon imaging by extended detection and computational reconstruction},
volume = {27},
month = {Jul},
year = {2019},
url = {http://www.opticsexpress.org/abstract.cfm?URI=oe-27-15-20117},
doi = {10.1364/OE.27.020117}
}
2018
W. Cheng, L. Xu, L. Han and L. Fang,
Proc. of The 26th ACM International Conference on Multimedia (MM '18). (Oral)
Aiming at autonomous, adaptive and real-time human body reconstruction technique, this paper presents iHuman3D: an intelligent human body 3D reconstruction system using a single aerial robot integrated with an RGB-D camera. Specifically, we propose a real-time and active view planning strategy based on a highly efficient ray casting algorithm in GPU and a novel information gain formulation directly in TSDF. We also propose the human body reconstruction module by revising the traditional volumetric fusion pipeline with a compactly-designed non-rigid deformation for slight motion of the human target. We unify both the active view planning and human body reconstruction in the same TSDF volume-based representation. Quantitative and qualitative experiments are conducted to validate that the proposed iHuman3D system effectively removes the constraint of extra manual labor, enabling real-time and autonomous reconstruction of human body.
Latex Bibtex Citation:
@inproceedings{10.1145/3240508.3240600,
author = {Cheng, Wei and Xu, Lan and Han, Lei and Guo, Yuanfang and Fang, Lu},
title = {IHuman3D: Intelligent Human Body 3D Reconstruction Using a Single Flying Camera},
year = {2018},
isbn = {9781450356657},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3240508.3240600},
doi = {10.1145/3240508.3240600},
booktitle = {Proceedings of the 26th ACM International Conference on Multimedia},
pages = {1733–1741},
numpages = {9},
keywords = {tsdf, human 3d reconstruction, next best view, flying camera},
location = {Seoul, Republic of Korea},
series = {MM '18}
}
L. Han and L. Fang,
Proc. of Robotics Science and Systems (RSS) , June 2018. (Oral)
Aiming at the practical usage of dense 3D recon-struction on portable devices, we propose FlashFusion, a Fast LArge-Scale High-resolution (sub-centimeter level) 3D recon-struction system without the use of GPU computing. It enables globally-consistent localization through a robust yet fast global bundle adjustment scheme, and realizes spatial hashing based volumetric fusion running at 300Hz and rendering at 25Hz via highly efficient valid chunk selection and mesh extraction schemes. Extensive experiments on both real world and synthetic datasets demonstrate that FlashFusion succeeds to enable real-time, globally consistent, high-resolution (5mm), and large-scale dense 3D reconstruction using highly-constrained computation,i.e., the CPU computing on portable device.
Latex Bibtex Citation:
@inproceedings{han2018flashfusion,
title={FlashFusion: Real-time Globally Consistent Dense 3D Reconstruction using CPU Computing.},
author={Han, Lei and Fang, Lu},
booktitle={Robotics: Science and Systems},
volume={1},
number={6},
pages={7},
year={2018}
}

Y. Guo, R. Wang, L. Fang and X. Cao,
IEEE Trans. on Image Processing (TIP) , May 2018.
In this paper, we carry out a performance analysis from a probabilistic perspective to introduce the error diffusion-based halftone visual watermarking (EDHVW) methods' expected performances and limitations. Then, we propose a new general EDHVW method, content aware double-sided embedding error diffusion (CaDEED), via considering the expected watermark decoding performance with specific content of the cover images and watermark, different noise tolerance abilities of various cover image content, and the different importance levels of every pixel (when being perceived) in the secret pattern (watermark). To demonstrate the effectiveness of CaDEED, we propose CaDEED with expectation constraint (CaDEED-EC) and CaDEED-noise visibility function (NVF) and importance factor (IF) (CaDEED-N&I). Specifically, we build CaDEED-EC by only considering the expected performances of specific cover images and watermark. By adopting the NVF and proposing the IF to assign weights to every embedding location and watermark pixel, respectively, we build the specific method CaDEED-N&I. In the experiments, we select the optimal parameters for NVF and IF via extensive experiments. In both the numerical and visual comparisons, the experimental results demonstrate the superiority of our proposed work.
Latex Bibtex Citation:
@ARTICLE{8314752, author={Y. {Guo} and O. C. {Au} and R. {Wang} and L. {Fang} and X. {Cao}}, journal={IEEE Transactions on Image Processing}, title={Halftone Image Watermarking by Content Aware Double-Sided Embedding Error Diffusion}, year={2018}, volume={27}, number={7}, pages={3387-3402}, doi={10.1109/TIP.2018.2815181}}

H. Zheng, M. Ji, H. Wang, Y. Liu and L. Fang,
Proc. of European conference on computer vision (ECCV), 2018.
The Reference-based Super-resolution (RefSR) super-resolves a low-resolution (LR) image given an external high-resolution (HR) reference image, where the reference image and LR image share similar viewpoint but with significant resolution gap x8. Existing RefSR methods work in a cascaded way such as patch matching followed by synthesis pipeline with two independently defined objective functions, leading to the inter-patch misalignment, grid effect and inefficient optimization. To resolve these issues, we present CrossNet, an end-to-end and fully-convolutional deep neural network using cross-scale warping. Our network contains image encoders, cross-scale warping layers, and fusion decoder: the encoder serves to extract multi-scale features from both the LR and the reference images; the cross-scale warping layers spatially aligns the reference feature map with the LR feature map; the decoder finally aggregates feature maps from both domains to synthesize the HR output. Using cross-scale warping, our network is able to perform spatial alignment at pixel-level in an end-to-end fashion, which improves the existing schemes both in precision (around 2dB-4dB) and efficiency (more than 100 times faster).
Latex Bibtex Citation:
@inproceedings{zheng2018crossnet,
title={CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping},
author={Zheng, Haitian and Ji, Mengqi and Wang, Haoqian and Liu, Yebin and Fang, Lu},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={88--104},
year={2018}
}

H. Wang, W. P An, X. Wang, and L. Fang,
Proc. of IEEE International Conference on Multimedia and Expo (ICME), 2018. (Oral)
We propose a novel method for multi-person 2D pose estimation. Our model zooms in the image gradually, which we refer to as the Magnify-Net, to solve the bottleneck problem of mean average precision (mAP) versus pixel error. Moreover, we squeeze the network efficiently by an inspired design that increases the mAP while saving the processing time. It is a simple, yet robust, bottom-up approach consisting of one stage. The architecture is designed to detect the part position and their association jointly via two branches of the same sequential prediction process, resulting in a remarkable performance and efficiency rise. Our method outcompetes the previous state-of-the-art results on the challenging COCO key-points task and MPII Multi-Person Dataset.
Latex Bibtex Citation:
@INPROCEEDINGS{8486591, author={H. {Wang} and W. P. {An} and X. {Wang} and L. {Fang} and J. {Yuan}}, booktitle={2018 IEEE International Conference on Multimedia and Expo (ICME)}, title={Magnify-Net for Multi-Person 2D Pose Estimation}, year={2018}, volume={}, number={}, pages={1-6}, doi={10.1109/ICME.2018.8486591}}

H. Wang, Y. Zhou, X. Wang, and L. Fang,
Proc. of International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018.
This paper presents a method for stereoscopic image stitching, which can make stereoscopic images look as natural as possible. Our method combines a constrained projective warp and a shape-preserving warp to reduce the projective distortion and the vertical disparity of the stitched image. In addition to provide a good alignment accuracy and maintain the consistency of input stereoscopic images, we add a specific restriction into the projective warp, which establishes the connection between target left and right images. To optimize the whole warp, a energy term is designed. It can constrain the shape of straight line and vertical disparity. Experimental results on a variety of stereoscopic images can ensure the efficiency of the proposed method.
Latex Bibtex Citation:
H. Wang, Y. Zhou, X. Wang and L. Fang, "A Natural Shape-Preserving Stereoscopic Image Stitching," 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 2018, pp. 1812-1816, doi: 10.1109/ICASSP.2018.8461411.
2017
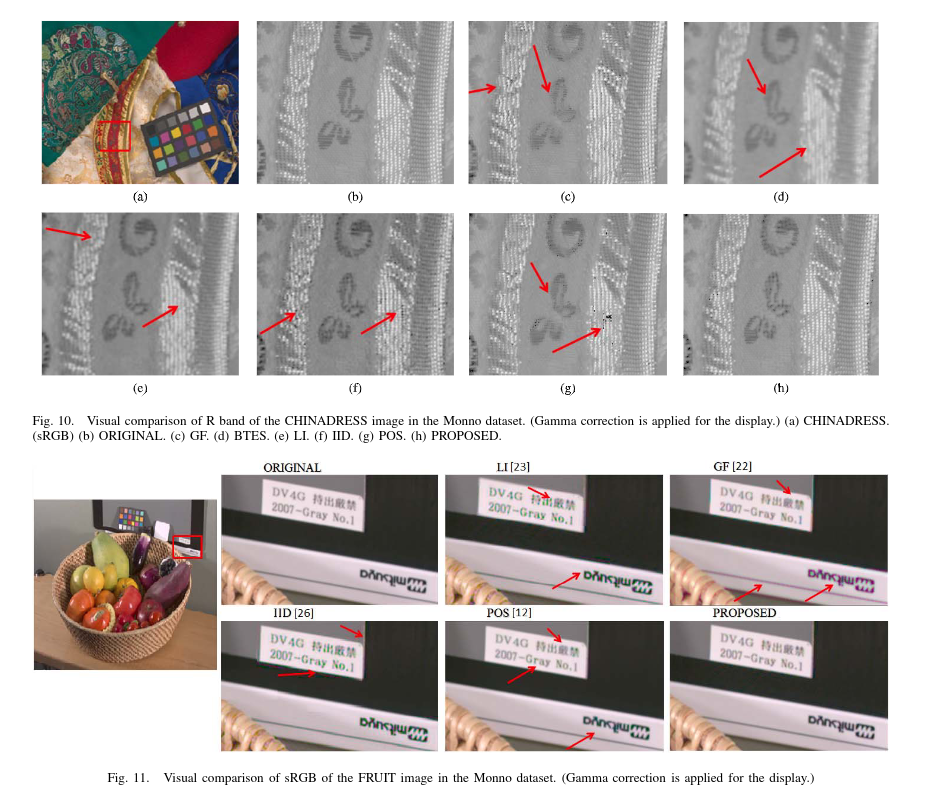
S. Jaiswal and L. Fang,
IEEE Trans. on Image Processing (TIP), Vol. 26, No. 2, pp. 953-968, Feb. 2017.
Color filter array (CFA) interpolation, or three-band demosaicking, is a process of interpolating the missing color samples in each band to reconstruct a full color image. In this paper, we are concerned with the challenging problem of multispectral demosaicking, where each band is significantly undersampled due to the increment in the number of bands. Specifically, we demonstrate a frequency-domain analysis of the subsampled color-difference signal and observe that the conventional assumption of highly correlated spectral bands for estimating undersampled components is not precise. Instead, such a spectral correlation assumption is image dependent and rests on the aliasing interferences among the various color-difference spectra. To address this problem, we propose an adaptive spectral-correlation-based demosaicking (ASCD) algorithm that uses a novel anti-aliasing filter to suppress these interferences, and we then integrate it with an intra-prediction scheme to generate a more accurate prediction for the reconstructed image. Our ASCD is computationally very simple, and exploits the spectral correlation property much more effectively than the existing algorithms. Experimental results conducted on two data sets for multispectral demosaicking and one data set for CFA demosaicking demonstrate that the proposed ASCD outperforms the state-of-the-art algorithms.
Latex Bibtex Citation:
@ARTICLE{7762719, author={S. P. {Jaiswal} and L. {Fang} and V. {Jakhetiya} and J. {Pang} and K. {Mueller} and O. C. {Au}}, journal={IEEE Transactions on Image Processing}, title={Adaptive Multispectral Demosaicking Based on Frequency-Domain Analysis of Spectral Correlation}, year={2017}, volume={26}, number={2}, pages={953-968}, doi={10.1109/TIP.2016.2634120}}

M. Ji, J. Gall, H. Zheng, Y. Liu and L. Fang,
Proc. of IEEE International Conference on Computer Vision (ICCV), Oct. 2017.
This paper proposes an end-to-end learning framework for multiview stereopsis. We term the network SurfaceNet. It takes a set of images and their corresponding camera parameters as input and directly infers the 3D model. The key advantage of the framework is that both photo-consistency as well geometric relations of the surface structure can be directly learned for the purpose of multiview stereopsis in an end-to-end fashion. SurfaceNet is a fully 3D convolutional network which is achieved by encoding the camera parameters together with the images in a 3D voxel representation. We evaluate SurfaceNet on the large-scale DTU benchmark.
Latex Bibtex Citation:
@INPROCEEDINGS{8237515, author={M. {Ji} and J. {Gall} and H. {Zheng} and Y. {Liu} and L. {Fang}}, booktitle={2017 IEEE International Conference on Computer Vision (ICCV)}, title={SurfaceNet: An End-to-End 3D Neural Network for Multiview Stereopsis}, year={2017}, volume={}, number={}, pages={2326-2334}, doi={10.1109/ICCV.2017.253}}

L. Han and L. Fang,
IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Sept. 2017. (Oral)
In this paper a binary feature based Loop Closure Detection (LCD) method is proposed, which for the first time achieves higher precision-recall (PR) performance compared with state-of-the-art SIFT feature based approaches. The proposed system originates from our previous work Multi-Index hashing for Loop closure Detection (MILD), which employs Multi-Index Hashing (MIH) [1] for Approximate Nearest Neighbor (ANN) search of binary features. As the accuracy of MILD is limited by repeating textures and inaccurate image similarity measurement, burstiness handling is introduced to solve this problem and achieves considerable accuracy improvement. Additionally, a comprehensive theoretical analysis on MIH used in MILD is conducted to further explore the potentials of hashing methods for ANN search of binary features from probabilistic perspective. This analysis provides more freedom on best parameter choosing in MIH for different application scenarios. Experiments on popular public datasets show that the proposed approach achieved the highest accuracy compared with state-of-the-art while running at 30Hz for databases containing thousands of images.
Latex Bibtex Citation:
@INPROCEEDINGS{8206261, author={L. {Han} and G. {Zhou} and L. {Xu} and L. {Fang}}, booktitle={2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title={Beyond SIFT using binary features in Loop Closure Detection}, year={2017}, volume={}, number={}, pages={4057-4063}, doi={10.1109/IROS.2017.8206261}}
L. Han and L. Fang,
Proc. of IEEE International Conference on Multimedia and Expo (ICME), July 2017. (Best Student Paper Award)
Loop Closure Detection (LCD) has been proved to be extremely useful in global consistent visual Simultaneously Localization and Mapping (SLAM) and appearance-based robot relocalization. Methods exploiting binary features in bag of words representation have recently gained a lot of popularity for their efficiency, but suffer from low recall due to the inherent drawback that high dimensional binary feature descriptors lack well-defined centroids. In this paper, we propose a realtime LCD approach called MILD (Multi-Index Hashing for Loop closure Detection), in which image similarity is measured by feature matching directly to achieve high recall without introducing extra computational complexity with the aid of Multi-Index Hashing (MIH). A theoretical analysis of the approximate image similarity measurement using MIH is presented, which reveals the trade-off between efficiency and accuracy from a probabilistic perspective. Extensive comparisons with state-of-the-art LCD methods demonstrate the superiority of MILD in both efficiency and accuracy.
Latex Bibtex Citation:
@INPROCEEDINGS{8019479, author={L. {Han} and L. {Fang}}, booktitle={2017 IEEE International Conference on Multimedia and Expo (ICME)}, title={MILD: Multi-index hashing for appearance based loop closure detection}, year={2017}, volume={}, number={}, pages={139-144}, doi={10.1109/ICME.2017.8019479}}
X. Yuan, L. Fang, D. Brady, Y. Liu and Q. Dai,
Proc. of IEEE International Conference on Computational Photography (ICCP), May 2017.(Oral)
We present a multi-scale camera array to capture and synthesize gigapixel videos in an efficient way. Our acquisition setup contains a reference camera with a short-focus lens to get a large field-of-view video and a number of unstructured long-focus cameras to capture local-view details. Based on this new design, we propose an iterative feature matching and image warping method to independently warp each local-view video to the reference video. The key feature of the proposed algorithm is its robustness to and high accuracy for the huge resolution gap (more than 8x resolution gap between the reference and the local-view videos), camera parallaxes, complex scene appearances and color inconsistency among cameras. Experimental results show that the proposed multi-scale camera array and cross resolution video warping scheme is capable of generating seamless gigapixel video without the need of camera calibration and large overlapping area constraints between the local-view cameras.
Latex Bibtex Citation:
@INPROCEEDINGS{7951481, author={X. {Yuan} and L. {Fang} and Q. {Dai} and D. J. {Brady} and Y. {Liu}}, booktitle={2017 IEEE International Conference on Computational Photography (ICCP)}, title={Multiscale gigapixel video: A cross resolution image matching and warping approach}, year={2017}, volume={}, number={}, pages={1-9}, doi={10.1109/ICCPHOT.2017.7951481}}
2016

J. Zeng, L. Fang, J. Pang, H. Li and F. Wu,
IEEE Trans. on Image Processing (TIP), Vol. 25, No. 12, pp. 5841 - 5856, Dec. 2016.
The subpixel rendering technology increases the apparent resolution of an LCD/OLED screen by exploiting the physical property that a pixel is composed of RGB individually addressable subpixels. Due to the intrinsic intercoordination between apparent luminance resolution and color fringing artifact, a common method of subpixel image assessment is subjective evaluation. In this paper, we propose a unified subpixel image quality assessment metric called subpixel image assessment (SPA), which syncretizes local subpixel and global pixel features. Specifically, comprehensive subjective studies are conducted to acquire data of user preferences. Accordingly, a collection of low-level features is designed under extensive perceptual validation, capturing subpixel and pixel features, which reflect local details and global distance from the original image. With the features and their measurements as the basis, the SPA is obtained, which leads to a good representation of the subpixel image characteristics. The experimental results justify the effectiveness and the superiority of the SPA. The SPA is also successfully adopted in a variety of applications, including content adaptive sampling and metric-guided image compression.
Latex Bibtex Citation:
@ARTICLE{7583723, author={J. {Zeng} and L. {Fang} and J. {Pang} and H. {Li} and F. {Wu}}, journal={IEEE Transactions on Image Processing}, title={Subpixel Image Quality Assessment Syncretizing Local Subpixel and Global Pixel Features}, year={2016}, volume={25}, number={12}, pages={5841-5856}, doi={10.1109/TIP.2016.2615429}}
L. Fang, Y. Xiang, N.M. Cheung and F. Wu,
IEEE Trans. on Image Processing (TIP), Vol. 25, No. 5, pp.1961 - 1976, Mar. 2016.
We propose an analytical model to estimate the depth-error-induced virtual view synthesis distortion (VVSD) in 3D video, taking the distance between reference and virtual views (virtual view position) into account. In particular, we start with a comprehensive preanalysis and discussion over several possible VVSD scenarios. Taking intrinsic characteristic of each scenario into consideration, we specifically classify them into four clusters: 1) overlapping region; 2) disocclusion and boundary region; 3) edge region; and 4) infrequent region. We propose to model VVSD as the linear combination of the distortion under different scenarios (DDSs) weighted by the probability under different scenarios (PDSs). We show analytically that DDS and PDS can be related to the virtual view position using quadratic/biquadratic models and linear models, respectively. Experimental results verify that the proposed model is capable of estimating the relationship between VVSD and the distance between reference and virtual views. Therefore, our model can be used to inform a reference view setup for capturing, or distortion at certain virtual view positions, when depth information is compressed.
Latex Bibtex Citation:
@ARTICLE{7430323, author={L. {Fang} and Y. {Xiang} and N. {Cheung} and F. {Wu}}, journal={IEEE Transactions on Image Processing}, title={Estimation of Virtual View Synthesis Distortion Toward Virtual View Position}, year={2016}, volume={25}, number={5}, pages={1961-1976}, doi={10.1109/TIP.2016.2535345}}

Q. Lu, W. Zhou, L. Fang and H. Li,
IEEE Trans. on Image Processing (TIP), Vol. 25, No. 5, pp.2311 - 2323, Feb. 2016.
As the unique identification of a vehicle, license plate is a key clue to uncover over-speed vehicles or the ones involved in hit-and-run accidents. However, the snapshot of over-speed vehicle captured by surveillance camera is frequently blurred due to fast motion, which is even unrecognizable by human. Those observed plate images are usually in low resolution and suffer severe loss of edge information, which cast great challenge to existing blind deblurring methods. For license plate image blurring caused by fast motion, the blur kernel can be viewed as linear uniform convolution and parametrically modeled with angle and length. In this paper, we propose a novel scheme based on sparse representation to identify the blur kernel. By analyzing the sparse representation coefficients of the recovered image, we determine the angle of the kernel based on the observation that the recovered image has the most sparse representation when the kernel angle corresponds to the genuine motion angle. Then, we estimate the length of the motion kernel with Radon transform in Fourier domain. Our scheme can well handle large motion blur even when the license plate is unrecognizable by human. We evaluate our approach on real-world images and compare with several popular state-of-the-art blind image deblurring algorithms. Experimental results demonstrate the superiority of our proposed approach in terms of effectiveness and robustness.
Latex Bibtex Citation:
@ARTICLE{7422106, author={Q. {Lu} and W. {Zhou} and L. {Fang} and H. {Li}}, journal={IEEE Transactions on Image Processing}, title={Robust Blur Kernel Estimation for License Plate Images From Fast Moving Vehicles}, year={2016}, volume={25}, number={5}, pages={2311-2323}, doi={10.1109/TIP.2016.2535375}}

Y. Zhou, T. Do, H. Zheng, N. Cheung and L. Fang,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), Aug.2016.
In this paper, we address the segmentation problem under limited computation and memory resources. Given a segmentation algorithm, we propose a framework that can reduce its computation time and memory requirement simultaneously, while preserving its accuracy. The proposed framework uses standard pixel-domain downsampling and includes two main steps. Coarse segmentation is first performed on the downsampled image. Refinement is then applied to the coarse segmentation results. We make two novel contributions to enable competitive accuracy using this simple framework. First, we rigorously examine the effect of downsampling on segmentation using a signal processing analysis. The analysis helps to determine the uncertain regions, which are small image regions where pixel labels are uncertain after the coarse segmentation. Second, we propose an efficient minimum spanning tree-based algorithm to propagate the labels into the uncertain regions. We perform extensive experiments using several standard data sets. The experimental results show that our segmentation accuracy is comparable to state-of-the-art methods, while requiring much less computation time and memory than those methods.
Latex Bibtex Citation:
@ARTICLE{7543518, author={Y. {Zhou} and T. {Do} and H. {Zheng} and N. {Cheung} and L. {Fang}}, journal={IEEE Transactions on Circuits and Systems for Video Technology}, title={Computation and Memory Efficient Image Segmentation}, year={2018}, volume={28}, number={1}, pages={46-61}, doi={10.1109/TCSVT.2016.2600261}}
H. Zheng, L. Fang, M. Ji, M. Strese, Y. Özer and E. Steinbach,
IEEE Trans. on Multimedia (TMM), July 2016.
When a user scratches a hand-held rigid tool across an object surface, an acceleration signal can be captured, which carries relevant information about the surface material properties. More importantly, such haptic acceleration signals can be used together with surface images to jointly recognize the surface material. In this paper, we present a novel deep learning method dealing with the surface material classification problem based on a fully convolutional network, which takes the aforementioned acceleration signal and a corresponding image of the surface texture as inputs. Compared to the existing surface material classification solutions which rely on a careful design of hand-crafted features, our method automatically extracts discriminative features utilizing advanced deep learning methodologies. Experiments performed on the TUM surface material database demonstrate that our method achieves state-of-the-art classification accuracy robustly and efficiently.
Latex Bibtex Citation:
@ARTICLE{7530831, author={H. {Zheng} and L. {Fang} and M. {Ji} and M. {Strese} and Y. {Özer} and E. {Steinbach}}, journal={IEEE Transactions on Multimedia}, title={Deep Learning for Surface Material Classification Using Haptic and Visual Information}, year={2016}, volume={18}, number={12}, pages={2407-2416}, doi={10.1109/TMM.2016.2598140}}
2015 and before

J. Pang, L. Fang, J. Zeng, Y. Guo and K. Tang,
IEEE Trans. on Image Processing (TIP), Vol. 25, No. 3, pp.1017 - 1032, Dec. 2015.
Subpixel-based image scaling can improve the apparent resolution of displayed images by controlling individual subpixels rather than whole pixels. However, improved luminance resolution brings chrominance distortion, making it crucial to suppress color error while maintaining sharpness. Moreover, it is challenging to develop a scheme that is applicable for various subpixel arrangements and for arbitrary scaling factors. In this paper, we address the aforementioned issues by proposing a generalized continuous-domain analysis model, which considers the low-pass nature of the human visual system (HVS). Specifically, given a discrete image and a grid-like subpixel arrangement, the signal perceived by the HVS is modeled as a 2D continuous image. Minimizing the difference between the perceived image and the continuous target image leads to the proposed scheme, which we call continuous-domain analysis for subpixel-based scaling (CASS). To eliminate the ringing artifacts caused by the ideal low-pass filtering in CASS, we propose an improved scheme, which we call CASS with Laplacian-of-Gaussian filtering. Experiments show that the proposed methods provide sharp images with negligible color fringing artifacts. Our methods are comparable with the state-of-the-art methods when applied on the RGB stripe arrangement, and outperform existing methods when applied on other subpixel arrangements.
Latex Bibtex Citation:
@ARTICLE{7365454, author={J. {Pang} and L. {Fang} and J. {Zeng} and Y. {Guo} and K. {Tang}}, journal={IEEE Transactions on Image Processing}, title={Subpixel-Based Image Scaling for Grid-like Subpixel Arrangements: A Generalized Continuous-Domain Analysis Model}, year={2016}, volume={25}, number={3}, pages={1017-1032}, doi={10.1109/TIP.2015.2512381}}

H. Liu, X. Sun, F. Wu and L. Fang,
IEEE Trans. on Image Processing (TIP), Vol. 24, No. 11, pp.4637 - 4650, July 2015.
Deblurring saturated night images are a challenging problem because such images have low contrast combined with heavy noise and saturated regions. Unlike the deblurring schemes that discard saturated regions when estimating blur kernels, this paper proposes a novel scheme to deduce blur kernels from saturated regions via a novel kernel representation and advanced algorithms. Our key technical contribution is the proposed function-form representation of blur kernels, which regularizes existing matrix-form kernels using three functional components: 1) trajectory; 2) intensity; and 3) expansion. From automatically detected saturated regions, their skeleton, brightness, and width are fitted into the corresponding three functional components of blur kernels. Such regularization significantly improves the quality of kernels deduced from saturated regions. Second, we propose an energy minimizing algorithm to select and assign the deduced function-form kernels to partitioned image regions as the initialization for non-uniform deblurring. Finally, we convert the assigned function-form kernels into matrix form for more detailed estimation in a multi-scale deconvolution. Experimental results show that our scheme outperforms existing schemes on challenging real examples.
Latex Bibtex Citation:
@ARTICLE{7169560, author={H. {Liu} and X. {Sun} and L. {Fang} and F. {Wu}}, journal={IEEE Transactions on Image Processing}, title={Deblurring Saturated Night Image With Function-Form Kernel}, year={2015}, volume={24}, number={11}, pages={4637-4650}, doi={10.1109/TIP.2015.2461445}}
L. Fang, N. Cheung, D. Tian, A. Verto, H. Sun and O. C. Au,
IEEE Trans. on Image Processing (TIP), Vol. 23, No. 1, pp.185 - 199, Jan. 2014.
We propose an analytical model to estimate the synthesized view quality in 3D video. The model relates errors in the depth images to the synthesis quality, taking into account texture image characteristics, texture image quality, and the rendering process. Especially, we decompose the synthesis distortion into texture-error induced distortion and depth-error induced distortion. We analyze the depth-error induced distortion using an approach combining frequency and spatial domain techniques. Experiment results with video sequences and coding/rendering tools used in MPEG 3DV activities show that our analytical model can accurately estimate the synthesis noise power. Thus, the model can be used to estimate the rendering quality for different system designs.
Latex Bibtex Citation:
@ARTICLE{6648645, author={L. {Fang} and N. {Cheung} and D. {Tian} and A. {Vetro} and H. {Sun} and O. C. {Au}}, journal={IEEE Transactions on Image Processing}, title={An Analytical Model for Synthesis Distortion Estimation in 3D Video}, year={2014}, volume={23}, number={1}, pages={185-199}, doi={10.1109/TIP.2013.2287608}}
L. Fang, O. C. Au, A. K. Katsaggelos, N. Cheung and H. Li,
IEEE Trans. on Image Processing (TIP), Vol. 22, No. 10, pp.1057-7149, April 2013.
In general, subpixel-based downsampling can achieve higher apparent resolution of the down-sampled images on LCD or OLED displays than pixel-based downsampling. With the frequency domain analysis of subpixel-based downsampling, we discover special characteristics of the luma-chroma color transform choice for monochrome images. With these, we model the anti-aliasing filter design for subpixel-based monochrome image downsampling as a human visual system-based optimization problem with a two-term cost function and obtain a closed-form solution. One cost term measures the luminance distortion and the other term measures the chrominance aliasing in our chosen luma-chroma space. Simulation results suggest that the proposed method can achieve sharper down-sampled gray/font images compared with conventional pixel and subpixel-based methods, without noticeable color fringing artifacts.
Latex Bibtex Citation:
@ARTICLE{6514934, author={L. {Fang} and O. C. {Au} and N. {Cheung} and A. K. {Katsaggelos} and H. {Li} and F. {Zou}}, journal={IEEE Transactions on Image Processing}, title={Luma-Chroma Space Filter Design for Subpixel-Based Monochrome Image Downsampling}, year={2013}, volume={22}, number={10}, pages={3818-3829}, doi={10.1109/TIP.2013.2262288}}
L. Fang, O. C. Au and N. Cheung,
IEEE Signal Processing Magazine (SPM), Vol. 30, No. 3, pp.177 - 189, May 2013.
Subpixel rendering technologies take advantage of the subpixel structure of a display to increase the apparent resolution and to improve the display quality of text, graphics, or images. These techniques can potentially improve the apparent resolution because a single pixel on color liquid crystal display (LCD) or organic light-emitting diode (OLED) displays consists of several independently controllable colored subpixels. Applications of subpixel rendering are font rendering and image/video subsampling. By controlling individual subpixel values of neighboring pixels, it is possible to microshift the apparent position of a line to give greater details of text. Similarly, since the individual selectable components are increased threefold by controlling subpixels rather than pixels, subpixel-based subsampling can potentially improve the apparent resolution of a down-scaled image. However, the increased apparent luminance resolution often comes at the price of color fringing artifacts. A major challenge is to suppress chrominance distortion while maintaining apparent luminance sharpness. This column introduces subpixel arrangement in color displays, how subpixel rendering works, and several practical subpixel rendering applications in font rendering and image subsampling.
Latex Bibtex Citation:
@article{article,
author = {Fang, Lu and Au, Oscar and Cheung, Ngai-Man},
year = {2013},
month = {05},
pages = {177-189},
title = {Subpixel Rendering: From Font Rendering to Image Subsampling},
volume = {30},
journal = {Signal Processing Magazine, IEEE},
doi = {10.1109/MSP.2013.2241311}
}

J. Dai, O. C. Au, L. Fang, C. Pang and F. Zou,
IEEE Trans. On Circuits and System for Video Technology (TCSVT), Vol. 23, No.11, pp. 1873 - 1886, June 2013.
In this paper, we propose an advanced color image denoising scheme called multichannel nonlocal means fusion (MNLF), where noise reduction is formulated as the minimization of a penalty function. An inherent feature of color images is the strong interchannel correlation, which is introduced into the penalty function as additional prior constraints to expect a better performance. The optimal solution of the minimization problem is derived, consisting of constructing and fusing multiple nonlocal means (NLM) spanning all three channels. The weights in the fusion are optimized to minimize the overall mean squared denoising error, with the help of the extended and adapted Stein's unbiased risk estimator (SURE). Simulations on representative test images under various noise levels verify the improvement brought by the multichannel NLM, compared to the traditional single-channel NLM. In the meantime, MNLF provides competitive performance both in terms of the color peak signal-to-noise ratio and in perceptual quality when compared with other state-of-the-art benchmarks.
Latex Bibtex Citation:
@article{10.1109/TCSVT.2013.2269020,
author = {Dai, Jingjing and Au, Oscar C. and Fang, Lu and Pang, Chao and Zou, Feng and Li, Jiali},
title = {Multichannel Nonlocal Means Fusion for Color Image Denoising},
year = {2013},
issue_date = {November 2013},
publisher = {IEEE Press},
volume = {23},
number = {11},
issn = {1051-8215},
url = {https://doi.org/10.1109/TCSVT.2013.2269020},
doi = {10.1109/TCSVT.2013.2269020},
journal = {IEEE Trans. Cir. and Sys. for Video Technol.},
month = nov,
pages = {1873–1886},
numpages = {14}
}

L. Fang, O. C. Au, K. Tang, H. Wang and X. Wen,
IEEE Trans. On Circuits and Systems for Video Technology (TCSVT), Vol. 22, No. 5, pp. 740-753, Dec. 2011.
Subpixel-based down-sampling is a method that can potentially improve apparent resolution of a down-scaled image on LCD by controlling individual subpixels rather than pixels. However, the increased luminance resolution comes at price of chrominance distortion. A major challenge is to suppress color fringing artifacts while maintaining sharpness. We propose a new subpixel-based down-sampling pattern called diagonal direct subpixel-based down-sampling (DDSD) for which we design a 2-D image reconstruction model. Then, we formulate subpixel-based down-sampling as a MMSE problem and derive the optimal solution called minimum mean square error for subpixel-based down-sampling (MMSE-SD). Unfortunately, straightforward implementation of MMSE-SD is computational intensive. We thus prove that the solution is equivalent to a 2-D linear filter followed by DDSD, which is much simpler. We further reduce computational complexity using a small k × k filter to approximate the much larger MMSE-SD filter. To compare the performances of pixel and subpixel-based down-sampling methods, we propose two novel objective measures: normalized l 1 high frequency energy for apparent luminance sharpness and PSNR U(V) for chrominance distortion. Simulation results show that both MMSE-SD and MMSE-SD( k ) can give sharper images compared with conventional down-sampling methods, with little color fringing artifacts.
Latex Bibtex Citation:
@ARTICLE{6101564, author={L. {Fang} and O. C. {Au} and K. {Tang} and X. {Wen} and H. {Wang}}, journal={IEEE Transactions on Circuits and Systems for Video Technology}, title={Novel 2-D MMSE Subpixel-Based Image Down-Sampling}, year={2012}, volume={22}, number={5}, pages={740-753}, doi={10.1109/TCSVT.2011.2179458}}
X. Wen, O. C. Au, J. Xu, L. Fang and R. Cha,
IEEE Trans. On Circuits and Systems for Video Technology (TCSVT), Vol. 21, No. 2, Jan, 2011.
To achieve superior performance, rate-distortion optimized motion estimation (ME) for variable block size (RDO VBSME) is often used in state-of-the-art video coding systems such as the H.264 JM software. However, the complexity of RDO-VBSME is very high both for software and hardware implementations. In this paper, we propose a hardware-friendly ME algorithm called RDOMFS with a novel hardware-friendly rate-distortion (RD)-like cost function, and a hardware-friendly modified motion vector predictor. Simulation results suggest that the proposed RDOMFS can achieve essentially the same RD performance as RDO-VBSME in JM. We also propose a matching hardware architecture with a novel Smart Snake Scanning order which can achieve very high data re-use ratio and data throughout. It is also reconfigurable because it can achieve variable data re-use ratio and can process variable frame size. The design is implemented with TSMC 0.18 μm CMOS technology and costs 103 k gates. At a clock frequency of 63 MHz, the architecture achieves real-time 1920 × 1080 RDO-VBSME at 30 frames/s. At a maximum clock frequency of 250 MHz, it can process 4096 × 2160 at 30 frames/s.
Latex Bibtex Citation:
@ARTICLE{5688307, author={X. {Wen} and O. C. {Au} and J. {Xu} and L. {Fang} and R. {Cha} and J. {Li}}, journal={IEEE Transactions on Circuits and Systems for Video Technology}, title={Novel RD-Optimized VBSME With Matching Highly Data Re-Usable Hardware Architecture}, year={2011}, volume={21}, number={2}, pages={206-219}, doi={10.1109/TCSVT.2011.2106274}}
L. Fang, O. C. Au, Y. Chen, A. K. Katsaggelos, H. Wang and X. Wen,
IEEE Trans. on Multimedia (TMM), Vol. 14, No. 4, pp. 1359-1369, Mar. 2012.
A portable device such as a digital camera with a single sensor and Bayer color filter array (CFA) requires demosaicing to reconstruct a full color image. To display a high resolution image on a low resolution LCD screen of the portable device, it must be down-sampled. The two steps, demosaicing and down-sampling, influence each other. On one hand, the color artifacts introduced in demosaicing may be magnified when followed by down-sampling; on the other hand, the detail removed in the down-sampling cannot be recovered in the demosaicing. Therefore, it is very important to consider simultaneous demosaicing and down-sampling.
Latex Bibtex Citation:
@ARTICLE{6171859, author={L. {Fang} and O. C. {Au} and Y. {Chen} and A. K. {Katsaggelos} and H. {Wang} and X. {Wen}}, journal={IEEE Transactions on Multimedia}, title={Joint Demosaicing and Subpixel-Based Down-Sampling for Bayer Images: A Fast Frequency-Domain Analysis Approach}, year={2012}, volume={14}, number={4}, pages={1359-1369}, doi={10.1109/TMM.2012.2191269}}

L. Fang, O. C. Au, X. Wen and K. Tang,
APSIPA Trans. on Signal and Information Processing (TSIP), Vol. 1, No. 1, pp. 1-10, Jan.2012.(Open-access, Most-viewed paper in 2012)
Many of portable devices such as smart phones, portable multimedia players (PMP), and digital single-lens reflex (DSLR) cameras are capable of capturing high-resolution images (e.g. 10 mega-pixel in DSLR) or even video. The limited battery power supply in the portable devices often prevents these systems to use high-power large liquid crystal display (LCD). Instead, the portable devices often have a LCD screen with small physical size (e.g. 3 cm × 2 cm for Smartphone or DSLR) and with much lower pixel resolution (e.g. 0.15 mega-pixel for 480 × 320 display) than actual image/video resolution. Thus, the high-resolution image and video are down-sampled before being displayed. Unfortunately, the anti-aliasing filter often leads to rather severe blurring. Although the blurring may be minor when the viewing distance is large, it can be rather disturbing in portable applications due to the short viewing distance. To cope with the blurring problem, one possible solution is to use an LCD screen with higher resolution. But such hardware solution tends to be expensive and often not welcomed by the consumer electronic companies. Another possible solution is to continue to use the low-resolution LCD screen, but use some software technique to enhance the apparent image/video resolution. In this paper, we discuss a novel way to improve the apparent resolution of down-sampled image/video using a technique called subpixel rendering, which controls subpixel that is smaller than a pixel in a high-precision manner.
Latex Bibtex Citation:
@article{fang_au_tang_wen_2012, title={Increasing image resolution on portable displays by subpixel rendering – a systematic overview}, volume={1}, DOI={10.1017/ATSIP.2012.3}, journal={APSIPA Transactions on Signal and Information Processing}, publisher={Cambridge University Press}, author={Fang, Lu and Au, Oscar C. and Tang, Ketan and Wen, Xing}, year={2012}, pages={e1}}

L. Fang, H. Liu, F. Wu, X. Sun and H. Li,
Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014.
In this paper, we deal with the image deblurring problem in a completely new perspective by proposing separable kernel to represent the inherent properties of the camera and scene system. Specifically, we decompose a blur kernel into three individual descriptors (trajectory, intensity and point spread function) so that they can be optimized separately. To demonstrate the advantages, we extract one-pixel-width trajectories of blur kernels and propose a random perturbation algorithm to optimize them but still keeping their continuity. For many cases, where current deblurring approaches fall into local minimum, excellent deblurred results and correct blur kernels can be obtained by individually optimizing the kernel trajectories. Our work strongly suggests that more constraints and priors should be introduced to blur kernels in solving the deblurring problem because blur kernels have lower dimensions than images.
Latex Bibtex Citation:
@INPROCEEDINGS{6909765, author={L. {Fang} and H. {Liu} and F. {Wu} and X. {Sun} and H. {Li}}, booktitle={2014 IEEE Conference on Computer Vision and Pattern Recognition}, title={Separable Kernel for Image Deblurring}, year={2014}, volume={}, number={}, pages={2885-2892}, doi={10.1109/CVPR.2014.369}}